Okay, seeing as my previous architecture thread didn't seem to draw a lot of flak, I guess most of it was at least semi-rational. I hope.
However, I'm trying to puzzle a way around congestion based lag, and I'd like to ramble about it where it can get critique. Pick it apart as best you can please.
Apologies if this seems long and drawn out, it is. But I hope you'll find it a relatively interesting read.
I mentioned a relevance layer previously, and since what I'm talking about relies on the concept, I'll describe it here, along with a brief description of the architecture.
Architecture:
A game instance is run on one or more machines (boxes) and consists of a three kinds of processes - a game database server (pretty standard), a 'master' (world) server and a number of generic 'slave' (zone) servers, which operate in a heirarchy. There need only be one server process running on any given box, but there can only be one 'master' within a cluster (sometimes referred to as a microcluster).
Edit: Connected clients are handled through a connection object which migrates between server processes as clients move around. The overall structure of the system looks sort of like this:

Relevance Graph:
The game universe in the system is not broken up into rectangular 2d zones, but instead is organised more like a heirarchical (sp?) scenegraph, with network-aware areas of variable size. This is referred to as the 'relevance graph'.
Nodes in this graph can be thought of as 'points of relevance', and coincide with physical features, such as rooms, areas of terrain, etc. Actors and other objects in the game universe a 'relevance limpets' and are *always* attached to a point of relevance.
The relevance graph is used to determine event relevance within the game system, both at the network and simulation layers. Anything that happens in a point of relevance is 'most likely' going to be important to everything contained in it. Neighbouring points may only receive events of a certain type (a soundproof, sealed glass box might only receive visually-oriented messages). The graph allows a designer to set what spreads how at any point in the world. Events also have a given radius of effect which is checked with the relevance graph as well. Neighbourhood is not used here to imply physcial adjacency, just that events of certain types occuring within (or passing through) one point of relevance may affect another. Absence of neighbourhood implies that points should have NO bearing on each other.
Shortcuts are used around this system in some places, where a specific entity is the target of an event. The master
server maintains a list of where all entities are, so a message can be efficiently delivered without propogating along the heirarchy as normal.
A server process is given a node of the relevance graph to deal with, and it deals with that and all points leafward (generally 'contained by') of that point, unless another server takes control. Slave servers are also informed of a master, which will manage the addition of slaves. Slaves are informed of neighbour or child relations with other slaves, so direct communication amongst themselves is possible.
All of the points of relevance that a server process has control over are referred to as its 'domain'. A domain, functionally, is close to a traditional mmorpg zone, whereas the point of relevance is more conceptually similar.
Update process:
Updating the relevance graph occurs in three phases, all of which occur in one server 'tick' in the server update threads.
The threads on each of the servers in a microcluster are brought into sync during this process.
Firstly, a logical update runs, which fires the events from their generators and adds them to any relevant recipients. High priority UDP is used to transfer these across server boundaries if required. This process must complete before the second phase can begin. This phase is started by the master server and triggers the process in slaves through a cascade effect.
The second phase of the update is the handling of receivers that have had an event passed to them. This may include the addition of messages to those receivers' outbound queues, including appropriate network messages to an avatar's associated client. This process occurs simultaneously on all server processes in the microcluster, and is synchronised (started, flagged finished) by the master server. Multi processor servers may utilise worker threads to process more than one part of the heirarchy simultaneously.
The final phase is network transmission (incoming messages are handled by a separate thread) to clients - this is done on each server in batches, a POR at a time. Firstly out of date or obsolete empirical state updates are discarded from the outbound queues, then those queues are processed and sent. This process has an overall timeout value, and unsent messages are preserved for the next cycle (and are sent in order/priority). Timeout occurences indicate congestion in the area and mark the process as congested. Timing and data stats are kept for data transmission and time to transmit at each POR and can be used to determine where the congestion is actually occurring. UNDER time exits (early finish) for this process is also recorded by the server process. Stats are transferred up to the master server regularly for congestion detection and handling.
Illustrative example (edit):
Consider the diagram below:
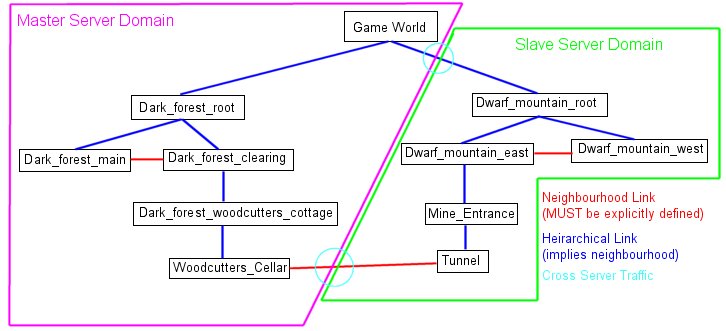
Each box represents a node in the relevance graph. Here we have a simple game world where the two areas, Dark Forest and Dwarf Mountain are segregated. Both are 'adventuring areas' and it's assumed the player base will usually be evenly split between these two areas. As such, Dwarf Mountain has been assigned to a slave server.
The heirarchies in each domain exhibit internal neighbourhood - Dark_forest_main, the POR that models the bulk of the Dark Forest is designated as a neighbour of the Dark_forest_clearing. Any message generated in either of these can have an effect (subject to range, etc) on the other.
Cross-server neighbourhood is illustrated between the cellar, and the tunnel. This is a good example of where the population can be kept low (limited numbers will fit in a cellar or tunnel) to limit the amount of traffic between the two POR's.
Parent-child relationships imply neighbourhood (what happens in the clearing is heard and seen in the cottage and vice versa) but only by one step - what happens in the clearing is NOT seen or heard in the cellar.
Considerations:
I expect the majority of traffic to be chat and object-description exchange. Such traffic should mostly be contained within a single server, with descriptions being drawn from cache, not database. Cross-server traffic is likely to be '/tells' or events occuring 'at the edges' of a server boundary. Good (physical) world design should keep this low.
I don't want to enforce a 'zone limit' for occupancy unless I can possibly help it, apart from areas where such a limit makes sense (typically room-like areas). This is an option open to a game designer, and although potentially useful is not a requisite of the library I'm building.
I do want to allow more than 50 players to gather in a quiet location and let them meet without them lagging up an entire server, especially somebody's combat. In games where real-time (or almost real-time) combat is used this would be highly annoying.
There are a *lot* of mobiles wandering around the world. The system is NOT designed to cope with 'blanket coverage' of players, but more with uneven distributions. Mobiles are aggregated and simplified when not visible to a player, and indeed can usually be aggregated even when visible.
The system's designed to be configured at startup (before players connect) so the master server can inform all the various slaves what they need to manage and allow time for load up and synchronisation of the abstract simulation layer (simplified geography and demographics used for statistical simulation of mobiles, resources etc). This takes some time.
Congestion here I define as the situation where the network exchange TO CLIENTS in the server process update times out significantly and persistently, apparently due to traffic to an isolatable (leaf) point of relevance.
Note that traffic is measured in complete UDP message sizes. Packet storming is a server security issue and is dealt with at the UDP level itself.
The strategy I have in mind is as follows:
Defining significant as a point where more than 10% of network traffic is left over still to process persistently;
Defining persistently as for a period of approximately 3 second, or proportionately less if the volume of outstanding network traffic (congestion) increases.
On detecting a congestion situation in a server process, we locate areas of congestion within that process' - first looking at leaf nodes averages, then progress up the relevance heirarchy until a disproportionate congestive average is found at a certain layer. We eventually determine an area of the heirarchy that is responsible for the congestion, and know how much traffic it has pending, how much it typically generates, and also the statistics of all processes, and as a result each box running such processes in the microcluster.
What I can't decide is what to do with the guilty chunk of heirarchy once it's identified, and I'm trying to think of ways of reintegrating the heirarchy once it's no longer necessary to be segregated from its greater body - and indeed how to judge that situation.
When such a segment of the relevance graph is definitely causing congestion it seems obvious to transfer ownership of that chunk to a quieter process. This has the obvious flaw of causing fragmentation of the relevance graph, which is a Bad Thing. I need to come up with a means of determining whether the cost of transferring a chunk of the graph is worthwhile, and some form of 'defragging' the graph occasionally.
Does anyone know of any systems that do this, or has anyone got any ideas for things I might need to track to make this work efficiently?
Sorry for the (exceedingly) long post, but hey, I'm scratching my head... and I need coffee.
[Edited by - _winterdyne_ on September 19, 2005 5:49:04 AM]







