A* speed

Author
Hello GameDevs,
I recently did an implementation of the A* algorithm. I'm pretty satisfied with the result as this is my first real 'adventure' in the area of AI (I have been programming for about 7 years). The implementation delivers results pretty quick and accurate.
While implementing a question came to mind, how fast is fast?
Here are some images of the implementation in practice:
Agent moving a long distance

Agent moving through a maze

Two videos showing the implementation in practice:
Video 1
Video 2
To see how fast my implementation worked I did a stresstest. I made the program calculate thousands of paths from random startpoints to random endpoints in my grid. I did this in an empty grid of 40 by 23, an obstacle-filled grid of 40 by 23 and an empty grid of 100 by 100.
These are the results:
40 by 23, no obstacles

100 by 100, no obstacles
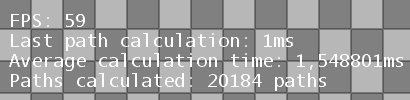
40 by 23, difficult terrain
Note that I'm mainly concerned about the average calculation time, as you can see, at the 40 by 23 grid with a difficult terrain there is an average calculation time of about 8ms. Also note that I don't have diagonal search, only horizontal and vertical.
My question to the GameDev boards; Is this an acceptable speed, can it be categorized as fast, or slow?
Discuss...
Thanks in advance,

I think you can double the speed on mostly empty areas by spreading from both the start and end and finding the path when the 2 areas collide somewhere, but in a tight maze it might be slower...
Author
I think you can double the speed on mostly empty areas by spreading from both the start and end and finding the path when the 2 areas collide somewhere, but in a tight maze it might be slower...
That is indeed something to think about. In practice though the world is probably not empty (otherwise there is no point to A*), so I don't know if it would make that much of a difference though.

That is indeed something to think about. In practice though the world is probably not empty (otherwise there is no point to A*), so I don't know if it would make that much of a difference though.
It depends upon the context. For example, the Fallout 3 and New Vegas worlds are by no means empty, but there are still large flat(ish) areas that could bog down A*.

I think you can double the speed on mostly empty areas by spreading from both the start and end and finding the path when the 2 areas collide somewhere, but in a tight maze it might be slower...
You have to be careful with that, as you could easily double your running time too. Imagine the start in the top left corner, and end in the bottom right. The search from the start could go down the bottom and then to the right, while the search from the end could to go the top and then to the left, completely missing each other. You could also have the start and end on a diagonal, but just off by one, and the two searches could go by each other the entire time but just miss each other.
For Dijkstra's, it just might be effective, but for A* I'd be really careful with that.
Hi, I am pretty new with A*. I have implemented one but somehow I face a weird path of A*. Would you like to help me? Thanks

Hi, I am pretty new with A*. I have implemented one but somehow I face a weird path of A*. Would you like to help me? Thanks
You should probably start a new thread (so you don't hijack this one) and post some code of what you're doing in your program so people can help you. I'm sure there would be people willing to help

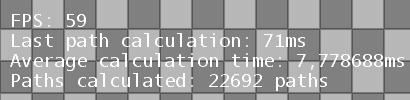
@OP: 71ms for a 40x23 map seems like a longish time to me (I know, the average is ~7.8). Was that just a weird burp in the system (i.e. maybe another process was started up that consumed some of the CPU and the OS gave less CPU time slices), or did you see ~71ms more than once?
I'm not sure how fast it compares to professional games, so I can't tell you that. Have you run it with a profiler to find your bottlenecks though?
Author
@OP: 71ms for a 40x23 map seems like a longish time to me (I know, the average is ~7.8). Was that just a weird burp in the system (i.e. maybe another process was started up that consumed some of the CPU and the OS gave less CPU time slices), or did you see ~71ms more than once?
71ms is indeed a long time. I'm not realy sure why, but sometimes the calc-time spikes. Could have something to do with with some other program running at the same time (maybe the snipping tool I used for screenshot?). I'm not realy worrying as the average is way lower. Sometimes it's also way lower then average.
I'm not sure how fast it compares to professional games, so I can't tell you that. Have you run it with a profiler to find your bottlenecks though?
Good tip, will do! I will post the results.
I just see the first picture of the stresstest isn't right, replacing it right now!
Author
I just tested my implementation on a 100x100 randomly generated world (1 in 10 tiles are blocked). After about a second I consistently get a Stack Overflow error. Is this because I use lists to store my closed nodes?

This topic is closed to new replies.
Advertisement
Popular Topics


Advertisement
