Edit: See the newest version in this post
New phases have been added: Turbulence and Avalanche.
--
Hello everybody, I'm looking for some feedback on an encryption technique/algorithm I've been working on for the past few days: PinWheel (PNWL) encryption.
Now, I've found that explaining how the technique works is a challenge in and of itself, so please bear with me – I've even included lots of pictures.
Before I get to how the algorithm works, here are some statistics:
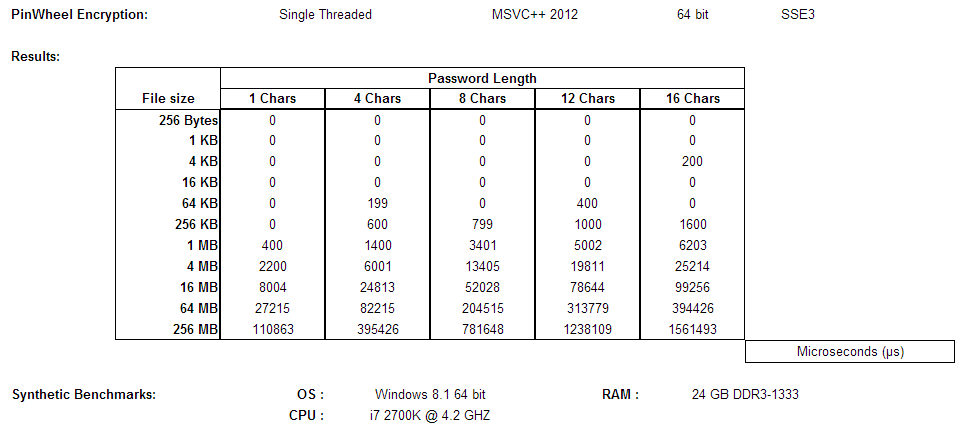
Basic Information About PNWL:
- Operates on 256 Byte Blocks
- Makes heavy use of XOR
- “Spins” the data to achieve encryption
- Strength of encryption is exponentially proportional to the password length
Essentially PNWL works by splitting up 256 bytes of data into sized blocks. Sort of like this:
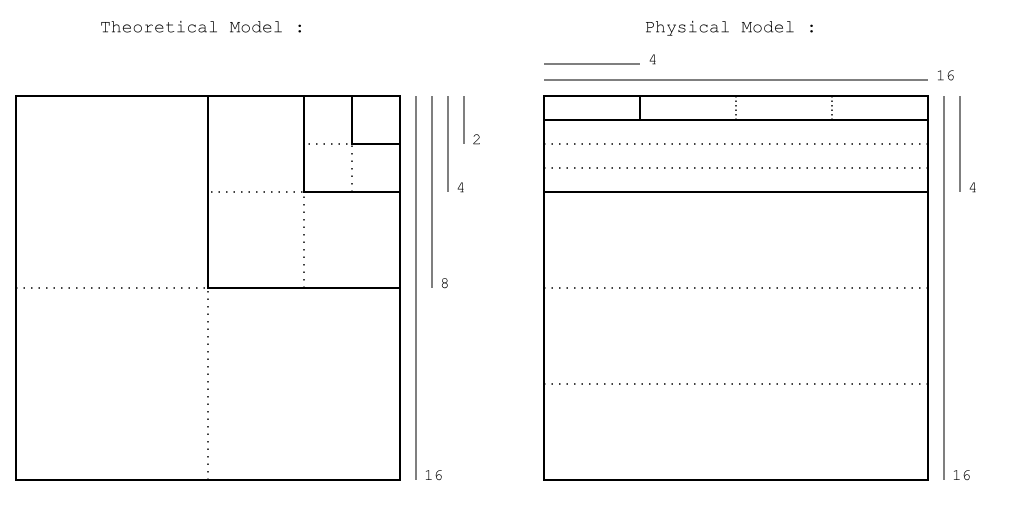
Thus, one block of 256 bytes (the main block) contains four blocks of 64 bytes; each of these blocks contains four blocks of 16 bytes, and similarly each of these blocks contain four blocks of 4 bytes.
To encrypt the data each block's content is quartered and then spun clockwise. As the quartered block spins, its content is internally XOR'd.
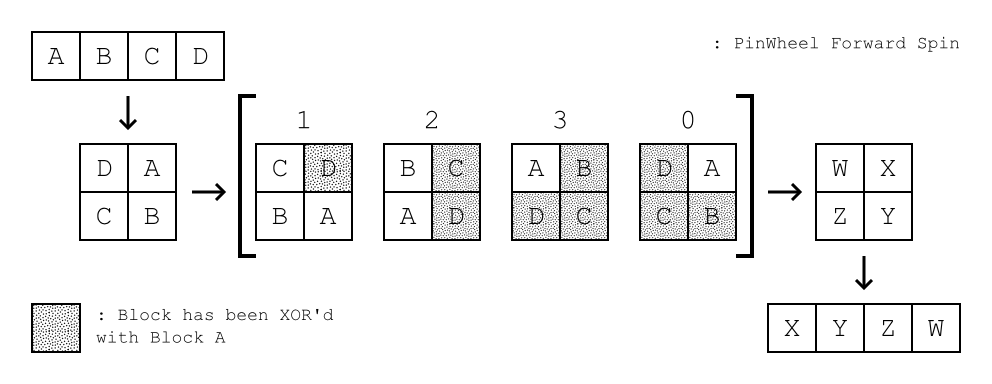
This hierarchy of spins is repeated for each character in the password. Furthermore, the magnitude of each spin is determined by the respective char.
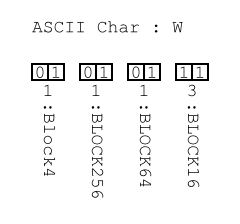
The only exception to the “Spin” technique are the Block4's, which instead “roll.” The amount of roll is determined by a set of magic numbers:
MAGIC[4][4] = { { 1, 3, 5, 7}, { 1, 7, 2, 9}, { 2, 3, 5, 7}, { 1, 9, 9, 6} };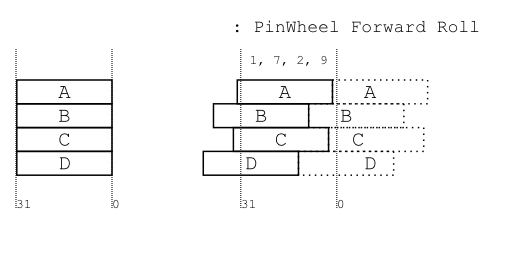
To encrypt:
For each character in the password:
- Roll Block4's Left
- Spin Bloc16's
- Spin Block64's
- Spin the Block256
To decrypt:
Reverse the password, and then for each character:
- Spin the Block256 in reverse
- Spin the Block64's in reverse
- Spin the Block16's in reverse
- Roll Block4's Right
Anyways enough talk; here's the code, which also attached (note: requires SSE3)
//Copyright (C) 2013 Laurence King
//
//Permission is hereby granted, free of charge, to any person obtaining a
//copy of this software and associated documentation files (the "Software"),
//to deal in the Software without restriction, including without limitation
//the rights to use, copy, modify, merge, publish, distribute, sublicense,
//and/or sell copies of the Software, and to permit persons to whom the
//Software is furnished to do so, subject to the following conditions:
//
//The above copyright notice and this permission notice shall be included
//in all copies or substantial portions of the Software.
//
//THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED,
//INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A
//PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT
//HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION
//OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE
//SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
#pragma once
#include <intrin.h>
#ifdef _MSC_VER
#define ALIGN( n ) __declspec( align( n ) )
#else
#define ALIGN( n ) alignas( n )
#endif
#define PNWL_MASK1 0x3
#define PNWL_MASK2 0xC
#define PNWL_MASK3 0x30
#define PNWL_MASK4 0xC0
namespace PinWheel
{
typedef int int32;
typedef unsigned int uint32;
// PNWL Magic constants
const uint32 MAGIC[4][4] = { { 1, 3, 5, 7}, { 1, 7, 2, 9}, { 2, 3, 5, 7}, { 1, 9, 9, 6} };
ALIGN(16)
struct Block16
{
union
{
uint32 Data[4];
__m128i vData;
};
void Spin0 (void);
void Spin1 (void);
void Spin2 (void);
void Spin3 (void);
void rSpin0 (void);
void rSpin1 (void);
void rSpin2 (void);
void rSpin3 (void);
};
ALIGN(16)
struct Block64
{
union
{
uint32 _Data[16];
Block16 Blocks[4];
__m128i vData [4];
};
void Spin0 (void);
void Spin1 (void);
void Spin2 (void);
void Spin3 (void);
void rSpin0 (void);
void rSpin1 (void);
void rSpin2 (void);
void rSpin3 (void);
};
ALIGN(16)
struct Block256
{
union
{
uint32 _Data[64];
__m128i _vData[16];
Block16 _Block16[16];
Block64 Blocks[4];
};
void Spin0 (void);
void Spin1 (void);
void Spin2 (void);
void Spin3 (void);
void rSpin0 (void);
void rSpin1 (void);
void rSpin2 (void);
void rSpin3 (void);
void Forward(const char *);
void Reverse(const char *);
};
#define ROTATE_LEFT(x, n) (((x) << (n)) | ((x) >> (32-(n))))
#define ROTATE_RIGHT(x, n) (((x) >> (n)) | ((x) << (32-(n))))
void Block16::Spin0(void)
{
Data[3] ^= Data[0];
Data[2] ^= Data[0];
Data[1] ^= Data[0];
Data[0] = ~Data[0];
}
void Block16::Spin1(void)
{
Data[3] ^= Data[0];
vData = _mm_shuffle_epi32(vData, _MM_SHUFFLE(2, 1, 0, 3));
}
void Block16::Spin2(void)
{
Data[3] ^= Data[0];
Data[2] ^= Data[0];
Data[0] = ~Data[0];
vData = _mm_shuffle_epi32(vData, _MM_SHUFFLE(1, 0, 3, 2));
}
void Block16::Spin3(void)
{
Data[3] ^= Data[0];
Data[2] ^= Data[0];
Data[1] ^= Data[0];
vData = _mm_shuffle_epi32(vData, _MM_SHUFFLE(0, 3, 2, 1));
}
void Block16::rSpin0(void)
{
Data[0] = ~Data[0];
Data[1] ^= Data[0];
Data[2] ^= Data[0];
Data[3] ^= Data[0];
}
void Block16::rSpin1(void)
{
vData = _mm_shuffle_epi32(vData, _MM_SHUFFLE(0, 3, 2, 1));
Data[3] ^= Data[0];
}
void Block16::rSpin2(void)
{
vData = _mm_shuffle_epi32(vData, _MM_SHUFFLE(1, 0, 3, 2));
Data[0] = ~Data[0];
Data[2] ^= Data[0];
Data[3] ^= Data[0];
}
void Block16::rSpin3(void)
{
vData = _mm_shuffle_epi32(vData, _MM_SHUFFLE(2, 1, 0, 3));
Data[3] ^= Data[0];
Data[2] ^= Data[0];
Data[1] ^= Data[0];
}
void Block64::Spin0(void)
{
vData[3] = _mm_xor_si128(vData[0], vData[3]);
vData[2] = _mm_xor_si128(vData[0], vData[2]);
vData[1] = _mm_xor_si128(vData[0], vData[1]);
}
void Block64::Spin1(void)
{
__m128i val_a = vData[0];
vData[0] = _mm_xor_si128(vData[3], val_a);
vData[3] = vData[2]; // _mm_xor_si128(vData[2], val_a);
vData[2] = vData[1]; // _mm_xor_si128(vData[1], val_a);
vData[1] = val_a;
}
void Block64::Spin2(void)
{
__m128i val_ab = vData[0];
vData[0] = _mm_xor_si128(vData[2], val_ab);
vData[2] = val_ab;
val_ab = vData[1];
vData[1] = _mm_xor_si128(vData[3], val_ab);
vData[3] = val_ab;
}
void Block64::Spin3(void)
{
__m128i val_a = vData[0];
vData[0] = _mm_xor_si128(vData[1], val_a);
vData[1] = _mm_xor_si128(vData[2], val_a);
vData[2] = _mm_xor_si128(vData[3], val_a);
vData[3] = val_a;
}
void Block64::rSpin0(void)
{
vData[3] = _mm_xor_si128(vData[0], vData[3]);
vData[2] = _mm_xor_si128(vData[0], vData[2]);
vData[1] = _mm_xor_si128(vData[0], vData[1]);
}
void Block64::rSpin1(void)
{
__m128i val_a = vData[1];
vData[1] = vData[2];
vData[2] = vData[3];
vData[3] = _mm_xor_si128(vData[0], val_a);
vData[0] = val_a;
}
void Block64::rSpin2(void)
{
__m128i val_ab = vData[2];
vData[2] = _mm_xor_si128(vData[0], val_ab);
vData[0] = val_ab;
val_ab = vData[3];
vData[3] = _mm_xor_si128(vData[1], val_ab);
vData[1] = val_ab;
}
void Block64::rSpin3(void)
{
__m128i val_a = vData[3];
vData[3] = _mm_xor_si128(vData[2], val_a);
vData[2] = _mm_xor_si128(vData[1], val_a);
vData[1] = _mm_xor_si128(vData[0], val_a);
vData[0] = val_a;
}
void Block256::Spin0(void)
{
_vData[0x4] = _mm_xor_si128(_vData[0x0], _vData[0x4]);
_vData[0x8] = _mm_xor_si128(_vData[0x0], _vData[0x8]);
_vData[0xC] = _mm_xor_si128(_vData[0x0], _vData[0xC]);
_vData[0x5] = _mm_xor_si128(_vData[0x1], _vData[0x5]);
_vData[0x9] = _mm_xor_si128(_vData[0x1], _vData[0x9]);
_vData[0xD] = _mm_xor_si128(_vData[0x1], _vData[0xD]);
_vData[0x6] = _mm_xor_si128(_vData[0x2], _vData[0x6]);
_vData[0xA] = _mm_xor_si128(_vData[0x2], _vData[0xA]);
_vData[0xE] = _mm_xor_si128(_vData[0x2], _vData[0xE]);
_vData[0x7] = _mm_xor_si128(_vData[0x3], _vData[0x7]);
_vData[0xB] = _mm_xor_si128(_vData[0x3], _vData[0xB]);
_vData[0xF] = _mm_xor_si128(_vData[0x3], _vData[0xF]);
}
void Block256::Spin1(void)
{
__m128i val_ = _vData[0];
_vData[0x0] = _mm_xor_si128(val_, _vData[0xC]);
_vData[0xC] = _vData[0x8];
_vData[0x8] = _vData[0x4];
_vData[0x4] = val_;
val_ = _vData[1];
_vData[0x1] = _mm_xor_si128(val_, _vData[0xD]);
_vData[0xD] = _vData[0x9];
_vData[0x9] = _vData[0x5];
_vData[0x5] = val_;
val_ = _vData[2];
_vData[0x2] = _mm_xor_si128(val_, _vData[0xE]);
_vData[0xE] = _vData[0xA];
_vData[0xA] = _vData[0x6];
_vData[0x6] = val_;
val_ = _vData[3];
_vData[0x3] = _mm_xor_si128(val_, _vData[0xF]);
_vData[0xF] = _vData[0xB];
_vData[0xB] = _vData[0x7];
_vData[0x7] = val_;
}
void Block256::Spin2(void)
{
__m128i val_ = _vData[0];
_vData[0x0] = _mm_xor_si128(val_, _vData[0x8]);
_vData[0x8] = val_;
val_ = _vData[1];
_vData[0x1] = _mm_xor_si128(val_, _vData[0x9]);
_vData[0x9] = val_;
val_ = _vData[2];
_vData[0x2] = _mm_xor_si128(val_, _vData[0xA]);
_vData[0xA] = val_;
val_ = _vData[3];
_vData[0x3] = _mm_xor_si128(val_, _vData[0xB]);
_vData[0xB] = val_;
val_ = _vData[4];
_vData[0x4] = _mm_xor_si128(_vData[0x8], _vData[0xC]);
_vData[0xC] = val_;
val_ = _vData[5];
_vData[0x5] = _mm_xor_si128(_vData[0x9], _vData[0xD]);
_vData[0xD] = val_;
val_ = _vData[6];
_vData[0x6] = _mm_xor_si128(_vData[0xA], _vData[0xE]);
_vData[0xE] = val_;
val_ = _vData[7];
_vData[0x7] = _mm_xor_si128(_vData[0xB], _vData[0xF]);
_vData[0xF] = val_;
}
void Block256::Spin3(void)
{
__m128i val_ = _vData[0];
_vData[0x0] = _mm_xor_si128(val_, _vData[0x4]);
_vData[0x4] = _mm_xor_si128(val_, _vData[0x8]);
_vData[0x8] = _mm_xor_si128(val_, _vData[0xC]);
_vData[0xC] = val_;
val_ = _vData[1];
_vData[0x1] = _mm_xor_si128(val_, _vData[0x5]);
_vData[0x5] = _mm_xor_si128(val_, _vData[0x9]);
_vData[0x9] = _mm_xor_si128(val_, _vData[0xD]);
_vData[0xD] = val_;
val_ = _vData[2];
_vData[0x2] = _mm_xor_si128(val_, _vData[0x6]);
_vData[0x6] = _mm_xor_si128(val_, _vData[0xA]);
_vData[0xA] = _mm_xor_si128(val_, _vData[0xE]);
_vData[0xE] = val_;
val_ = _vData[3];
_vData[0x3] = _mm_xor_si128(val_, _vData[0x7]);
_vData[0x7] = _mm_xor_si128(val_, _vData[0xB]);
_vData[0xB] = _mm_xor_si128(val_, _vData[0xF]);
_vData[0xF] = val_;
}
void Block256::rSpin0(void)
{
_vData[0x4] = _mm_xor_si128(_vData[0x0], _vData[0x4]);
_vData[0x8] = _mm_xor_si128(_vData[0x0], _vData[0x8]);
_vData[0xC] = _mm_xor_si128(_vData[0x0], _vData[0xC]);
_vData[0x5] = _mm_xor_si128(_vData[0x1], _vData[0x5]);
_vData[0x9] = _mm_xor_si128(_vData[0x1], _vData[0x9]);
_vData[0xD] = _mm_xor_si128(_vData[0x1], _vData[0xD]);
_vData[0x6] = _mm_xor_si128(_vData[0x2], _vData[0x6]);
_vData[0xA] = _mm_xor_si128(_vData[0x2], _vData[0xA]);
_vData[0xE] = _mm_xor_si128(_vData[0x2], _vData[0xE]);
_vData[0x7] = _mm_xor_si128(_vData[0x3], _vData[0x7]);
_vData[0xB] = _mm_xor_si128(_vData[0x3], _vData[0xB]);
_vData[0xF] = _mm_xor_si128(_vData[0x3], _vData[0xF]);
}
void Block256::rSpin1(void)
{
__m128i val_ = _vData[4];
_vData[0x4] = _vData[0x8];
_vData[0x8] = _vData[0xC];
_vData[0xC] = _mm_xor_si128(val_, _vData[0x0]);
_vData[0x0] = val_;
val_ = _vData[5];
_vData[0x5] = _vData[0x9];
_vData[0x9] = _vData[0xD];
_vData[0xD] = _mm_xor_si128(val_, _vData[0x1]);
_vData[0x1] = val_;
val_ = _vData[6];
_vData[0x6] = _vData[0xA];
_vData[0xA] = _vData[0xE];
_vData[0xE] = _mm_xor_si128(val_, _vData[0x2]);
_vData[0x2] = val_;
val_ = _vData[7];
_vData[0x7] = _vData[0xB];
_vData[0xB] = _vData[0xF];
_vData[0xF] = _mm_xor_si128(val_, _vData[0x3]);
_vData[0x3] = val_;
}
void Block256::rSpin2(void)
{
__m128i val_ = _vData[8];
_vData[0x8] = _mm_xor_si128(val_, _vData[0x0]);
_vData[0x0] = val_;
val_ = _vData[9];
_vData[0x9] = _mm_xor_si128(val_, _vData[0x1]);
_vData[0x1] = val_;
val_ = _vData[0xA];
_vData[0xA] = _mm_xor_si128(val_, _vData[0x2]);
_vData[0x2] = val_;
val_ = _vData[0xB];
_vData[0xB] = _mm_xor_si128(val_, _vData[0x3]);
_vData[0x3] = val_;
val_ = _vData[0xC];
_vData[0xC] = _mm_xor_si128(_vData[0x0], _vData[0x4]);
_vData[0x4] = val_;
val_ = _vData[0xD];
_vData[0xD] = _mm_xor_si128(_vData[0x1], _vData[0x5]);
_vData[0x5] = val_;
val_ = _vData[0xE];
_vData[0xE] = _mm_xor_si128(_vData[0x2], _vData[0x6]);
_vData[0x6] = val_;
val_ = _vData[0xF];
_vData[0xF] = _mm_xor_si128(_vData[0x3], _vData[0x7]);
_vData[0x7] = val_;
}
void Block256::rSpin3(void)
{
__m128i val_ = _vData[0xC];
_vData[0xC] = _mm_xor_si128(val_, _vData[0x8]);
_vData[0x8] = _mm_xor_si128(val_, _vData[0x4]);
_vData[0x4] = _mm_xor_si128(val_, _vData[0x0]);
_vData[0x0] = val_;
val_ = _vData[0xD];
_vData[0xD] = _mm_xor_si128(val_, _vData[0x9]);
_vData[0x9] = _mm_xor_si128(val_, _vData[0x5]);
_vData[0x5] = _mm_xor_si128(val_, _vData[0x1]);
_vData[0x1] = val_;
val_ = _vData[0xE];
_vData[0xE] = _mm_xor_si128(val_, _vData[0xA]);
_vData[0xA] = _mm_xor_si128(val_, _vData[0x6]);
_vData[0x6] = _mm_xor_si128(val_, _vData[0x2]);
_vData[0x2] = val_;
val_ = _vData[0xF];
_vData[0xF] = _mm_xor_si128(val_, _vData[0xB]);
_vData[0xB] = _mm_xor_si128(val_, _vData[0x7]);
_vData[0x7] = _mm_xor_si128(val_, _vData[0x3]);
_vData[0x3] = val_;
}
void Block256::Forward(const char * key)
{
for(char c = *(key++); c != 0; c = *(key++))
{
uint32 amnt0 = c & PNWL_MASK1;
uint32 amnt1 = (c & PNWL_MASK2 ) >> 2;
uint32 amnt2 = (c & PNWL_MASK3 ) >> 4;
uint32 amnt3 = (c & PNWL_MASK4 ) >> 6;
#pragma region BLOCK4
for(int i = 0; i < 64; i+=4)
{
_Data[i] = ROTATE_LEFT( _Data[i] , MAGIC[amnt3][0] );
_Data[i + 1] = ROTATE_LEFT( _Data[i + 1] , MAGIC[amnt3][1] );
_Data[i + 2] = ROTATE_LEFT( _Data[i + 2] , MAGIC[amnt3][2] );
_Data[i + 3] = ROTATE_LEFT( _Data[i + 3] , MAGIC[amnt3][3] );
}
#pragma endregion
#pragma region BLOCK16
switch (amnt0)
{
case 0:
for(int i = 0; i < 16; i++)
_Block16[i].Spin0();
break;
case 1:
for(int i = 0; i < 16; i++)
_Block16[i].Spin1();
break;
case 2:
for(int i = 0; i < 16; i++)
_Block16[i].Spin2();
break;
case 3:
for(int i = 0; i < 16; i++)
_Block16[i].Spin3();
break;
}
#pragma endregion
#pragma region BLOCK64
switch (amnt1)
{
case 0:
Blocks[0].Spin0();
Blocks[1].Spin0();
Blocks[2].Spin0();
Blocks[3].Spin0();
break;
case 1:
Blocks[0].Spin1();
Blocks[1].Spin1();
Blocks[2].Spin1();
Blocks[3].Spin1();
break;
case 2:
Blocks[0].Spin2();
Blocks[1].Spin2();
Blocks[2].Spin2();
Blocks[3].Spin2();
break;
case 3:
Blocks[0].Spin3();
Blocks[1].Spin3();
Blocks[2].Spin3();
Blocks[3].Spin3();
break;
}
#pragma endregion
#pragma region BLOCK256
switch (amnt2)
{
case 0:
Spin0();
break;
case 1:
Spin1();
break;
case 2:
Spin2();
break;
case 3:
Spin3();
break;
}
#pragma endregion
}
}
// Expects the key to already have been reversed
void Block256::Reverse(const char * rKey)
{
for(char c = *(rKey++); c != 0; c = *(rKey++))
{
uint32 amnt0 = c & PNWL_MASK1;
uint32 amnt1 = (c & PNWL_MASK2 ) >> 2;
uint32 amnt2 = (c & PNWL_MASK3 ) >> 4;
uint32 amnt3 = (c & PNWL_MASK4 ) >> 6;
#pragma region BLOCK256
switch (amnt2)
{
case 0:
rSpin0();
break;
case 1:
rSpin1();
break;
case 2:
rSpin2();
break;
case 3:
rSpin3();
break;
}
#pragma endregion
#pragma region BLOCK64
switch (amnt1)
{
case 0:
Blocks[0].rSpin0();
Blocks[1].rSpin0();
Blocks[2].rSpin0();
Blocks[3].rSpin0();
break;
case 1:
Blocks[0].rSpin1();
Blocks[1].rSpin1();
Blocks[2].rSpin1();
Blocks[3].rSpin1();
break;
case 2:
Blocks[0].rSpin2();
Blocks[1].rSpin2();
Blocks[2].rSpin2();
Blocks[3].rSpin2();
break;
case 3:
Blocks[0].rSpin3();
Blocks[1].rSpin3();
Blocks[2].rSpin3();
Blocks[3].rSpin3();
break;
}
#pragma endregion
#pragma region BLOCK16
switch (amnt0)
{
case 0:
for(int i = 0; i < 16; i++)
_Block16[i].rSpin0();
break;
case 1:
for(int i = 0; i < 16; i++)
_Block16[i].rSpin1();
break;
case 2:
for(int i = 0; i < 16; i++)
_Block16[i].rSpin2();
break;
case 3:
for(int i = 0; i < 16; i++)
_Block16[i].rSpin3();
break;
}
#pragma endregion
#pragma region BLOCK4
for(int i = 0; i < 64; i+=4)
{
_Data[i] = ROTATE_RIGHT( _Data[i] , MAGIC[amnt3][0] );
_Data[i + 1] = ROTATE_RIGHT( _Data[i + 1] , MAGIC[amnt3][1] );
_Data[i + 2] = ROTATE_RIGHT( _Data[i + 2] , MAGIC[amnt3][2] );
_Data[i + 3] = ROTATE_RIGHT( _Data[i + 3] , MAGIC[amnt3][3] );
}
#pragma endregion
}
}
}
And here is how you would encrypt some data:
PinWheel::Block256 * blocks = reinterpret_cast<PinWheel::Block256 *>(memblock);
for(int i = 0; i < blockcount; i++)
{
blocks[i].Forward(password.data());
}
Now for some visual examples of PNWL encryption in action:
(For illustration purposes, these were created by encrypting the image portion of either 24bpp bitmaps or grayscale bitmaps)
Mona:
[spoiler]Original:
Short Password (4 char): 
Medium Password ( 8 char): 
Long Password (12 char): 
[/spoiler]
Simple Triangles:
[spoiler]Original: 
Short Password ( 4 char): 
Medium Password (8 char): 
Long Password (12 char):  [/spoiler]
[/spoiler]
Flower ( grayscale bitmap)
[spoiler]Original: 
Short Password (4 char): 
Medium Password ( 8 char ) : 
Long Password ( 12 char ) : 
[/spoiler]
Where I can see improvement: PNWL was designed to make use of SIMD commands, however it can be done without them.
I don't have a processor that supports AVX2, but I predict a 30% boost if it was used, for example, on the Roll portion. Furthermore, multithreading could yield excellent returns
Attached is the source code for PNWL and a quick console app to test it out.
Thank you


")