This series has since been revised and combinedIn the last article you learned the basics of finite state machines and saw a simple application. As promised, we will now explore a much more interesting use for FSMs: regular expressions. If the topic of regular expressions is familiar to you, feel free to skip the first section, since it serves as a basic introduction to the subject. [size="5"]Regular expressions (regexes) Think of an identifier in C++ (such as this, temp_var2, assert etc.). How would you describe what qualifies for an identifier? Lets see if we remember... an identifier consists of letters, digits and the underscore character (_), and must start with a letter (it's possible to start with an underscore, but better not to, as these identifiers are reserved by the language). A regular expression is a notation that allows us to define such things precisely: letter (letter | digit | underscore) * In regular expressions, the vertical bar | means "or", the parentheses are used to group sub expressions (just like in math) and the asterisk (*) means "zero or more instances of the previous". So the regular expression above defines the set of all C++ identifiers (a letter followed by zero or more letters, digits or underscores). Lets see some more examples:
- abb*a - all words starting with a, ending with a, and having at least one b in-between. For example: "aba", "abba", "abbbba" are words that fit, but "aa" or "abab" are not.
- 0|1|2|3|4|5|6|7|8|9 - all digits. For example: "1" is a digit, "fx" is not.
- x(y|z)*(a|b|c) - all words starting with x, then zero or more y or z, and end with a, b or c. For example: "xa", "xya", "xzc", "xyzzzyzyyyzb".
- xyz - only the word "xyz".
bool recognize(string str)
{
string::size_type len = str.length();
// can't be shorter than 3 chars
if (len < 3)
return false;
// last 3 chars must be "abb"
if (str.substr(len - 3, 3) != "abb")
return false;
// must contain no chars other than "a" and "b"
if (str.find_first_not_of("ab") != string::npos)
return false;
return true;
}
It's pretty clean and robust - it will recognize (a|b)*abb and reject anything else. However, it is clear that the techniques employed in the code are very "personal" to the regex at hand.
If we slightly change the regex to (a|b)*abb(a|b)*, for instance (all sequences of a's and b's that have abb somewhere in them), it would change the algorithm completely. (We'd then probably want to go over the string, a char at a time and record the appearance of abb. If the string ends and abb wasn't found, it's a rejection, etc.). It seems that for each regex, we should think of some algorithm to handle it, and this algorithm can be completely different from algorithms for other regexes.
So what is the solution? Is there any standartized way to handle regexes? Can we even dream of a general algorithm that can produce a recognizer function given a regex? We sure can (otherwise, what would this article be about :-) )! Read on.
[size="5"]FSMs to the rescue
It happens so that Finite State Machines are a very useful tool for regular expressions. More specifically, a regex (any regex!) can be represented as an FSM. To show how, however, we must present two additional definitions (which actually are very logical, assuming we use a FSM for a regex).
- A start state is the state in which a FSM starts.
- An accepting state is a final state in which the FSM returns with some answer.
state = start_state
input = get_next_input
while not end of input do
state = move(state, input)
input = get_next_input
end
if state is a final state
return "ACCEPT"
else
return "REJECT"
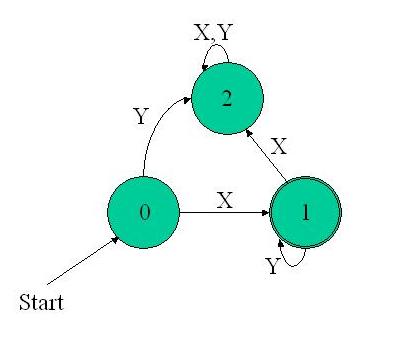
The algorithm is presented in very general terms and should be well understood. Lets "run" it on the simple xy* FSM, with the input "xyy". We start from the start state - 0; Get next input: x, end of input ? not yet; move(0, x) moves us to state 1; input now becomes y; not yet end of input; move(1, y) moves us to state 1; exactly the same with the second y; now it's end of input; state 1 is a final state, so "ACCEPT";
Piece of cake isn't it ? Well, it really is ! It's a straightforward algorithm and a very easy one for the computer to execute.
Lets go back to the regex we started with - (a|b)*abb. Here is the FSM that represents (recognizes) it:
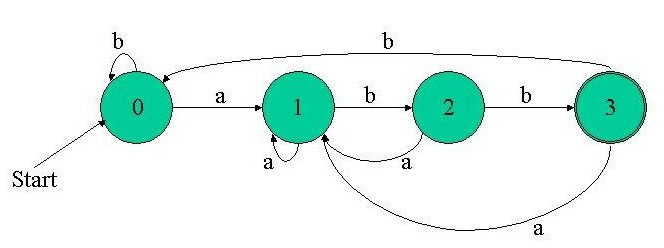
- Convert the regex to a FSM
- Write FSM code to recognize strings
#include
#include
#include
using namespace std;
typedef int fsm_state;
typedef char fsm_input;
bool is_final_state(fsm_state state)
{
return (state == 3) ? true : false;
}
fsm_state get_start_state(void)
{
return 0;
}
fsm_state move(fsm_state state, fsm_input input)
{
// our alphabet includes only 'a' and 'b'
if (input != 'a' && input != 'b')
assert(0);
switch (state)
{
case 0:
if (input == 'a')
{
return 1;
}
else if (input == 'b')
{
return 0;
}
break;
case 1:
if (input == 'a')
{
return 1;
}
else if (input == 'b')
{
return 2;
}
break;
case 2:
if (input == 'a')
{
return 1;
}
else if (input == 'b')
{
return 3;
}
break;
case 3:
if (input == 'a')
{
return 1;
}
else if (input == 'b')
{
return 0;
}
break;
default:
assert(0);
}
}
bool recognize(string str)
{
if (str == "")
return false;
fsm_state state = get_start_state();
string::const_iterator i = str.begin();
fsm_input input = *i;
while (i != str.end())
{
state = move(state, *i);
++i;
}
if (is_final_state(state))
return true;
else
return false;
}
// simple driver for testing
int main(int argc, char** argv)
{
recognize(argv[1]) ? cout << 1 : cout << 0;
return 0;
}
Take a good look at the recognize function. You should immediately see how closely it follows the FSM Simulation algorithm. The FSM is initialized to the start state, and the first input is read. Then, in a loop, the machine moves to its next state and fetches the next input, etc. until the input string ends. Eventually, we check whether we reached a final state.
Note that this recognize function will be the same for any regex. The only functions that change are the trivial is_final_state and get_start_state, and the more complicated transition function move. But move is very structural - it closely follows the graphical description of the FSM. As you'll see in future articles, such transition functions are easily generated from the description.
So, what have we got so far? We know how to write code that runs a state machine on a string. What don't we know? We still don't know how to generate the FSM from a regex. This is what the following articles are about. See you there!
[hr](C) Copyright by Eli Bendersky, 2003. All rights reserved.


