A video version of this article is now available at ">Introduction to UTF-8 on Youtube.
Introduction
When many first learn to program computers, they are often introduced to ASCII with or without knowing it. ASCII stands for "American Standard Code for Information Interchange" and when programmers use it, they are often talking about the character encoding scheme for the English alphabet. If you're using C or C++ and use the char data type to write strings, you're probably using ASCII. ASCII actually only uses 7 bits and is from 0 - 127. (There is an extended ASCII set, but in this article, only the original set will be considered.) This works well when you only want to use Latin letters in your programs, but in our more global world, we need to thinking about making programs that can display characters in other characters such as Korean, Chinese, or Japanese.
UNICODE was developed as a way to encode all of the characters for every language, but when we consider languages like Korean and Chinese, 8 bit characters just isn't enough. Windows programmers maybe familiar with UCS-2(2-byte Universal Character Set). UCS-2 is a 16 bit version of UNICODE and it can encode the values for all of the most common UNICODE characters. In UCS-2, all characters are exactly 16 bits. These days, Windows also supports UTF-16 as well which uses 16 bit values, but some characters can be composed of two 16 bit units. This works well on Windows and fits perfectly with the Windows 16 bit wchar_t type. For many who want to support different language characters and at the same time be able to support multiple platforms, this is not enough..
wchar_t has some disadvantages. For example, wchar_t is 16 bits on Windows, but 32 on some other platforms. Also when using wchar_t and even with UTF-16 and UTF-32, you have to worry about endianess. UTF-8 can be used as an alternative to this.
What is UTF8 and how is it encoded?
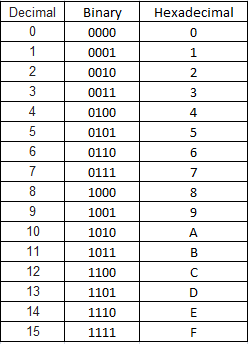
UTF-8 is a way to encode the UNICODE values. From this point forward, the word character in this article will be used to refer to the value of the character in unicode which goes from 1 through 1,112,064 with zero, which can be used as a string terminator. UTF-8 is a variable-sized encoding. In UTF-8, characters will code into eito either 1, 2, 3, or 4 bytes. 1 byte encodings are only for characters from 0 to 127 meaning if it's a 1 byte encoding it'll be equivilent to ASCII. 2 byte encodings are for characters from 128 to 2047. 3 byte encodings are for characters from 2048 to 65535 and 4 byte encodings are for characters from 65536 to 1,112,064. To understand how the encoding works, we'll need to examine the binary representation of each character's numeric value. To do this easily, I'll also use hexadecimal notation as one hexadecimal digit always corresponds to a 4 bit nibble. Here's a quick table.
So 2C (hexadecimal) = (2 X 16) + (12 X 1) = 48(decimal) and 0010 1100(binary)
I understand that many may know this already, but I want to make sure new programmers will be able to understand.
The UTF-8 Format
In UTF-8, the high-order bits in binary are important. UTF-8 works by using the leading high-order bits of the first byte to tell how many bytes were used to encode the value. For 8 bit encoding from 0 to 127, the high-order bit will always be zero. Because of this, if the high-order bit is zero, the byte will always be treated as a single byte encoding. Therefore, all single byte encodings have the following form: 0XXX XXXX
7 bits are available to code the number. Here is the format for all of the encodings:
Once you know the format of UTF-8, converting back and forth between it is fairly simple. To convert to UTF-8, you can easily see if it will encode to 1, 2, 3, or 4 bytes by checking the numerical range. Then copy the bits to the correct location.
Example Conversion
Let's try an example. I'm going to use hexadecimal value 1FACBD for this example. Now, I don't believe this is a real UNICODE character, but it'll help us see how to encode values. The number is greater than FFFF so it will require a 4-byte encoding. Let's see how it'll work. First, here's the value in binary.
This will be a 4-byte encoding so we'll need to use the following format.
Now converting to UTF-8 is as simple as copying the bits from right to left into the correct positions.
Like I said, UTF-8 is a fairly straight-forward format.
Advantages of UTF-8
If you want to support non-Latin characters, UTF-8 has a lot of advantages. Since it codes characters using one byte chunks and since UTF-8 strings will never contain a "null" byte, you can use UTF-8 strings with most traditional null-terminated string processing functions. More and more things are being encoded in UTF-8, especially things that are sent over the Internet. Many web pages are coded in UTF-8, and UTF-8 is often used with XML and JSON. Supporting UTF-8 will allow developers to retrieve text data from other sources without conversions. UTF-8 is also byte oriented and as long as it is read one byte at a time, you don't have to worry about endianess.
Here are some other advantages.
UTF-8 can encode UNICODE character without having to choose the correct "code page"
Character boundaries in UTF-8 can be easily identified for scanning in either direction. If corruption occurs, the beginning of the next valid character can easily be found. In UTF-16, if an odd number of bytes are missing from the middle, the entire rest of the string will be invalid.
Any byte-oriented string searching algorithm can be used with UTF-8 as the sequence used to code one character will never be used to code a different character.
UTF-8 can be encoded using only bit operations.
Disadvantages of UTF-8
To be fair, here are some disadvantages as well. There's often a trade-off between storage size and ease of processing so in many cases, UTF-8 will be larger than some other encodings.
It is possible to code other language text using a single-byte encoding as long as the "code page" has been set. Because of this, UTF-8 encoded text will be larger except for plain ASCII characters. In single- byte encodings that use 8-bit characters with non-Latin letters in the upper half (128-255) such as Cyrillic and Greek, UTF-8 will double the size. And in the case of single-byte encodings for languages like Thai and Hindi, UTF-8 will triple the size. This is because UTF-8 should be able to encode all characters without needing to figure out or set the code page.
If not handled correctly, it is possible for a UTF-8 string to be truncated in the middle of a character, resulting in an invalid string.
Codes in the range of 0800 to FFFF take three bytes in UTF-8, but only two in UTF-16. This includes East Asian scripts like Japanese, Chinese, and Korean.
Conclusion
Now it's not difficult converting back and forth between UTF-8. As a programmer who wants to use UNICODE, you have to decided whether or not it would it be better to continue to store things as wide character string, using UTF-8 only to store things in files or to use UTF-8 all of the time. If you want to support non-Latin characters, UTF-8 has a lot of advantages. Unless you need to do a lot of string manipulation, you can keep your strings in UTF-8 until you need to display them. Typical string operations like concatenation, copying, and finding sub-strings can be done directly in UTF-8. If you want to parse through all of the characters to show them in a GUI for example, you can create an iterator to go through each character. (Comment From Aressera). Using UTF-8 in code is not difficult to implement and if you're wondering how to add support for non-Latin characters, it's worth considering.
Additional References
ASCII Wiki - http://en.wikipedia.org/wiki/ASCII
UTF-8 Encoding - http://www.fileformat.info/info/unicode/utf8.htm
UTF-8 Wiki - http://en.wikipedia.org/wiki/UTF-8
Code page - http://en.wikipedia.org/wiki/Code_page
Article Update Log
4 Aug 2013: Initial Draft
6 Aug 2013: Updated Introductions and Conclusions
5 Dec 2013: Added Link to Video Version
This article was originally posted on the Squared'D Blog
An important feature of UTF-8 is that you always know whether a byte is the beginning of a sequence or not. So even if you're scanning a huge string backwards, you can just skip until you reach a byte that has the highest bit unset or the two highest bits both set to locate characters.
Though of course the index determined will then be a byte index, not a character index - which is actually quite convenient when storing UTF-8 in std::string and using other C or C++ standard library functions on it.
Some more arguments for UTF-8:
Another thing is byte order. UTF-16 and UTF-32 require a byte order mark to indicate whether the high byte or low byte comes first. UTF-8 is byte-oriented format and the standard requires it to be the same on both little endian and big endian systems.
Also, the fact that any plain ASCII text doubles as UTF-8 text is quite useful because you can seamlessly add UTF-8 capability to scripting languages and DSLs without requiring a re-encode of the script sources or adding unreliable encoding detection for the parser.
Why does UTF-8 (in a two-byte sequence) require three bits in the first byte, and two in the second byte? What information do those bits actually encode?
Why doesn't it just use, for example, one bit at the beginning of each byte that if 1, says "there's another byte coming also".
Why does the first byte (in a two-byte character) hold two bits (not three), and require an additional two bits for the second character?
That seems unneccesarily wasteful of bits - surely there's some important reason why they chose that?
As you mentioned, that gives a mere 2048 characters, when a basic naive implementation of a universal character system would allow two bytes to hold eight times that (16384 characters), letting more characters be encoded in less space.
Taking 11 bits from a 32-bit sequence means you lose 1/3rd of your potential. What's the purpose of those extra bits?
Can program-specific information be stored in those bits, such as layout information or styling?
Why does UTF-8 (in a two-byte sequence) require three bits in the first byte, and two in the second byte? What information do those bits actually encode?
You are correct. In UTF-8, characters over 2047 will require at least 3 bytes. The reason was is described in Cygon's quote below.
An important feature of UTF-8 is that you always know whether a byte is the beginning of a sequence or not. So even if you're scanning a huge string backwards, you can just skip until you reach a byte that has the highest bit unset or the two highest bits both set to locate characters.
There's a trade-off between storage size and ease of processing. It's not the most compact encoding, but as the maximum for UNICODE will always be four bytes, except in the worst case(only the most uncommon glyphs are used), UTF-8 will be smaller than using 4 bytes every time.
Also, from one of the references, "the bytes 0xFE and 0xFF do not appear, so a valid UTF-8 stream never matches the UTF-16 byte order mark and thus cannot be confused with it. The absence of 0xFF (0377) also eliminates the need to escape this byte in Telnet (and FTP control connection)."
I removed a passage from the original entry text about some code being available in the coming weeks - I don't consider the article to depend on it though. When the author has time to get the code ready, he'll be posting about it in his journal and I'll remind him to update the article as well.
I for one am not so happy with UTF-8 due to the differing character sizes. The article should also explain downsides as far as I'm concerned.
I'd really like so hear a statement from eastern countries how they value UTF-8. It's obviously tailored to latin letters hosing everybody else.
It's not all happy shiny world with UTF-8
These comments are very helpful. This article is only a few days old and the quality has improved because of comments like this. I added a list of some disadvantages of UTF-8. I think it's good to hear both sides of the argument and to know why certain decisions were made with the encoding.
I for one am not so happy with UTF-8 due to the differing character sizes.
What do you perceive to be the benefit of fixed-size encoding? It still doesn't allow you to assume that there is one character per codepoint (even in UTF-32, there are plenty of combined characters), and it doesn't simplify text layout (ideograms have some truly lovely layout rules).
It's not all happy shiny world with UTF-8
Are there any reasonable alternatives?
I'm not sure I know of a fully conforming UTF-16 implementation, and the lesser-used surrogate pairs are a constant source of bugs. UCS-2 can't encode all of unicode (though westerners will probably never notice the lack). And UTF-32, while conceptually simple, is a waste of space for everyone...
The benefit is when you're actually working inside a longer string (think text editor). Having one simple way to forward/backward through the character data beats converting back and forth.
As for alternatives, I do prefer UCS-2. But let's face it, there is no perfect solution. You merely can weigh disadvantages against each other :)
Just currently I'm fighting with ScintillaNet, which gives me hard times with their POSITION type (which is byte based) vs. the .NET string class. I'd be fine if Scintilla would allow both ways; or would provide converters.
The benefit is when you're actually working inside a longer string (think text editor). Having one simple way to forward/backward through the character data beats converting back and forth.
Yes, but you can't actually do that. Even in UTF-32 or UCS-2.
These are fixed mappings to codepoints, not characters. There are still a significant number of multi-codepoint sequences that a text editor has to treat as single characters.
Of course, you can ignore those entirely. But at that point, you don't need the astral plain characters anyway, so why bother with unicode?
[quote name="AmirTugi" timestamp="1382283283"]Excellent article.
Only did not understand one thing.
When converting '[color=#282828][font=helvetica, arial, verdana, tahoma, sans-serif]1FACBD' [/size][/font][/color]to UTF-8
Why do you check if it's bigger than FFFF, and thus it requires 4 bytes?
I understand it won't fit the 3 byte format, but how do you know it by looking at the number and at FFFF?[/quote]
With a 3 byte encoding, atmost 16 bits can be used to actually encode the number. Anything over FFFF will be atleast 17 bits. FFFF is the maximum value that can fit in a 3 byte encoding in UTF8.
Determining how to represent text can get a bit complicated once you start to get past the ASCII and the Latin alphabet. This article will examine UNICODE's UTF-8 encoding and how it can help.
 So 2C (hexadecimal) = (2 X 16) + (12 X 1) = 48(decimal) and 0010 1100(binary)
I understand that many may know this already, but I want to make sure new programmers will be able to understand.
So 2C (hexadecimal) = (2 X 16) + (12 X 1) = 48(decimal) and 0010 1100(binary)
I understand that many may know this already, but I want to make sure new programmers will be able to understand.
 Once you know the format of UTF-8, converting back and forth between it is fairly simple. To convert to UTF-8, you can easily see if it will encode to 1, 2, 3, or 4 bytes by checking the numerical range. Then copy the bits to the correct location.
Once you know the format of UTF-8, converting back and forth between it is fairly simple. To convert to UTF-8, you can easily see if it will encode to 1, 2, 3, or 4 bytes by checking the numerical range. Then copy the bits to the correct location.
 This will be a 4-byte encoding so we'll need to use the following format.
This will be a 4-byte encoding so we'll need to use the following format.
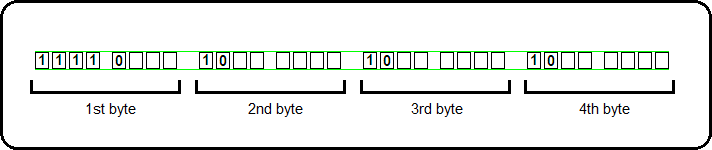 Now converting to UTF-8 is as simple as copying the bits from right to left into the correct positions.
Now converting to UTF-8 is as simple as copying the bits from right to left into the correct positions.
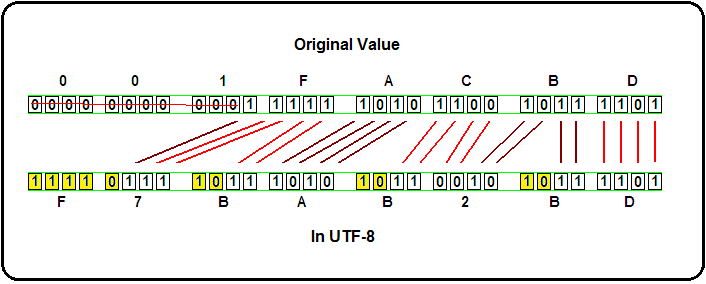 Like I said, UTF-8 is a fairly straight-forward format.
Like I said, UTF-8 is a fairly straight-forward format.












Since you mentioned indexing strings:
An important feature of UTF-8 is that you always know whether a byte is the beginning of a sequence or not. So even if you're scanning a huge string backwards, you can just skip until you reach a byte that has the highest bit unset or the two highest bits both set to locate characters.
Though of course the index determined will then be a byte index, not a character index - which is actually quite convenient when storing UTF-8 in std::string and using other C or C++ standard library functions on it.
Some more arguments for UTF-8:
Another thing is byte order. UTF-16 and UTF-32 require a byte order mark to indicate whether the high byte or low byte comes first. UTF-8 is byte-oriented format and the standard requires it to be the same on both little endian and big endian systems.
Also, the fact that any plain ASCII text doubles as UTF-8 text is quite useful because you can seamlessly add UTF-8 capability to scripting languages and DSLs without requiring a re-encode of the script sources or adding unreliable encoding detection for the parser.