This article uses material originally posted on Diligent Graphics web site.
Introduction
Graphics APIs have come a long way from small set of basic commands allowing limited control of configurable stages of early 3D accelerators to very low-level programming interfaces exposing almost every aspect of the underlying graphics hardware. Next-generation APIs, Direct3D12 by Microsoft and Vulkan by Khronos are relatively new and have only started getting widespread adoption and support from hardware vendors, while Direct3D11 and OpenGL are still considered industry standard. New APIs can provide substantial performance and functional improvements, but may not be supported by older hardware. An application targeting wide range of platforms needs to support Direct3D11 and OpenGL. New APIs will not give any advantage when used with old paradigms. It is totally possible to add Direct3D12 support to an existing renderer by implementing Direct3D11 interface through Direct3D12, but this will give zero benefits. Instead, new approaches and rendering architectures that leverage flexibility provided by the next-generation APIs are expected to be developed.
There are at least four APIs (Direct3D11, Direct3D12, OpenGL/GLES, Vulkan, plus Apple's Metal for iOS and osX platforms) that a cross-platform 3D application may need to support. Writing separate code paths for all APIs is clearly not an option for any real-world application and the need for a cross-platform graphics abstraction layer is evident. The following is the list of requirements that I believe such layer needs to satisfy:
- Lightweight abstractions: the API should be as close to the underlying native APIs as possible to allow an application leverage all available low-level functionality. In many cases this requirement is difficult to achieve because specific features exposed by different APIs may vary considerably.
- Low performance overhead: the abstraction layer needs to be efficient from performance point of view. If it introduces considerable amount of overhead, there is no point in using it.
- Convenience: the API needs to be convenient to use. It needs to assist developers in achieving their goals not limiting their control of the graphics hardware.
- Multithreading: ability to efficiently parallelize work is in the core of Direct3D12 and Vulkan and one of the main selling points of the new APIs. Support for multithreading in a cross-platform layer is a must.
- Extensibility: no matter how well the API is designed, it still introduces some level of abstraction. In some cases the most efficient way to implement certain functionality is to directly use native API. The abstraction layer needs to provide seamless interoperability with the underlying native APIs to provide a way for the app to add features that may be missing.
Diligent Engine is designed to solve these problems. Its main goal is to take advantages of the next-generation APIs such as Direct3D12 and Vulkan, but at the same time provide support for older platforms via Direct3D11, OpenGL and OpenGLES. Diligent Engine exposes common C++ front-end for all supported platforms and provides interoperability with underlying native APIs. It also supports integration with Unity and is designed to be used as graphics subsystem in a standalone game engine, Unity native plugin or any other 3D application. Full source code is available for download at GitHub and is free to use.
Overview
Diligent Engine API takes some features from Direct3D11 and Direct3D12 as well as introduces new concepts to hide certain platform-specific details and make the system easy to use. It contains the following main components:
Render device (IRenderDevice interface) is responsible for creating all other objects (textures, buffers, shaders, pipeline states, etc.).
Device context (IDeviceContext interface) is the main interface for recording rendering commands. Similar to Direct3D11, there are immediate context and deferred contexts (which in Direct3D11 implementation map directly to the corresponding context types). Immediate context combines command queue and command list recording functionality. It records commands and submits the command list for execution when it contains sufficient number of commands. Deferred contexts are designed to only record command lists that can be submitted for execution through the immediate context.
An alternative way to design the API would be to expose command queue and command lists directly. This approach however does not map well to Direct3D11 and OpenGL. Besides, some functionality (such as dynamic descriptor allocation) can be much more efficiently implemented when it is known that a command list is recorded by a certain deferred context from some thread.
The approach taken in the engine does not limit scalability as the application is expected to create one deferred context per thread, and internally every deferred context records a command list in lock-free fashion. At the same time this approach maps well to older APIs.
In current implementation, only one immediate context that uses default graphics command queue is created. To support multiple GPUs or multiple command queue types (compute, copy, etc.), it is natural to have one immediate contexts per queue. Cross-context synchronization utilities will be necessary.
Swap Chain (ISwapChain interface). Swap chain interface represents a chain of back buffers and is responsible for showing the final rendered image on the screen.
Render device, device contexts and swap chain are created during the engine initialization.
Resources (ITexture and IBuffer interfaces). There are two types of resources - textures and buffers. There are many different texture types (2D textures, 3D textures, texture array, cubmepas, etc.) that can all be represented by ITexture interface.
Resources Views (ITextureView and IBufferView interfaces). While textures and buffers are mere data containers, texture views and buffer views describe how the data should be interpreted. For instance, a 2D texture can be used as a render target for rendering commands or as a shader resource.
Pipeline State (IPipelineState interface). GPU pipeline contains many configurable stages (depth-stencil, rasterizer and blend states, different shader stage, etc.). Direct3D11 uses coarse-grain objects to set all stage parameters at once (for instance, a rasterizer object encompasses all rasterizer attributes), while OpenGL contains myriad functions to fine-grain control every individual attribute of every stage. Both methods do not map very well to modern graphics hardware that combines all states into one monolithic state under the hood. Direct3D12 directly exposes pipeline state object in the API, and Diligent Engine uses the same approach.
Shader Resource Binding (IShaderResourceBinding interface). Shaders are programs that run on the GPU. Shaders may access various resources (textures and buffers), and setting correspondence between shader variables and actual resources is called resource binding. Resource binding implementation varies considerably between different API. Diligent Engine introduces a new object called shader resource binding that encompasses all resources needed by all shaders in a certain pipeline state.
API Basics
Creating Resources
Device resources are created by the render device. The two main resource types are buffers, which represent linear memory, and textures, which use memory layouts optimized for fast filtering. Graphics APIs usually have a native object that represents linear buffer. Diligent Engine uses IBuffer interface as an abstraction for a native buffer. To create a buffer, one needs to populate BufferDesc structure and call IRenderDevice::CreateBuffer() method as in the following example:
BufferDesc BuffDesc;
BufferDesc.Name = "Uniform buffer";
BuffDesc.BindFlags = BIND_UNIFORM_BUFFER;
BuffDesc.Usage = USAGE_DYNAMIC;
BuffDesc.uiSizeInBytes = sizeof(ShaderConstants);
BuffDesc.CPUAccessFlags = CPU_ACCESS_WRITE;
m_pDevice->CreateBuffer( BuffDesc, BufferData(), &m_pConstantBuffer );While there is usually just one buffer object, different APIs use very different approaches to represent textures. For instance, in Direct3D11, there are ID3D11Texture1D, ID3D11Texture2D, and ID3D11Texture3D objects. In OpenGL, there is individual object for every texture dimension (1D, 2D, 3D, Cube), which may be a texture array, which may also be multisampled (i.e. GL_TEXTURE_2D_MULTISAMPLE_ARRAY). As a result there are nine different GL texture types that Diligent Engine may create under the hood. In Direct3D12, there is only one resource interface. Diligent Engine hides all these details in ITexture interface. There is only one IRenderDevice::CreateTexture() method that is capable of creating all texture types. Dimension, format, array size and all other parameters are specified by the members of the TextureDesc structure:
TextureDesc TexDesc;
TexDesc.Name = "My texture 2D";
TexDesc.Type = TEXTURE_TYPE_2D;
TexDesc.Width = 1024;
TexDesc.Height = 1024;
TexDesc.Format = TEX_FORMAT_RGBA8_UNORM;
TexDesc.Usage = USAGE_DEFAULT;
TexDesc.BindFlags = BIND_SHADER_RESOURCE | BIND_RENDER_TARGET | BIND_UNORDERED_ACCESS;
TexDesc.Name = "Sample 2D Texture";
m_pRenderDevice->CreateTexture( TexDesc, TextureData(), &m_pTestTex );If native API supports multithreaded resource creation, textures and buffers can be created by multiple threads simultaneously.
Interoperability with native API provides access to the native buffer/texture objects and also allows creating Diligent Engine objects from native handles. It allows applications seamlessly integrate native API-specific code with Diligent Engine.
Next-generation APIs allow fine level-control over how resources are allocated. Diligent Engine does not currently expose this functionality, but it can be added by implementing IResourceAllocator interface that encapsulates specifics of resource allocation and providing this interface to CreateBuffer() or CreateTexture() methods. If null is provided, default allocator should be used.
Initializing the Pipeline State
As it was mentioned earlier, Diligent Engine follows next-gen APIs to configure the graphics/compute pipeline. One big Pipelines State Object (PSO) encompasses all required states (all shader stages, input layout description, depth stencil, rasterizer and blend state descriptions etc.). This approach maps directly to Direct3D12/Vulkan, but is also beneficial for older APIs as it eliminates pipeline misconfiguration errors. With many individual calls tweaking various GPU pipeline settings it is very easy to forget to set one of the states or assume the stage is already properly configured when in fact it is not. Using pipeline state object helps avoid these problems as all stages are configured at once.
Creating Shaders
While in earlier APIs shaders were bound separately, in the next-generation APIs as well as in Diligent Engine shaders are part of the pipeline state object. The biggest challenge when authoring shaders is that Direct3D and OpenGL/Vulkan use different shader languages (while Apple uses yet another language in their Metal API). Maintaining two versions of every shader is not an option for real applications and Diligent Engine implements shader source code converter that allows shaders authored in HLSL to be translated to GLSL. To create a shader, one needs to populate ShaderCreationAttribs structure. SourceLanguage member of this structure tells the system which language the shader is authored in:
- SHADER_SOURCE_LANGUAGE_DEFAULT - The shader source language matches the underlying graphics API: HLSL for Direct3D11/Direct3D12 mode, and GLSL for OpenGL and OpenGLES modes.
- SHADER_SOURCE_LANGUAGE_HLSL - The shader source is in HLSL. For OpenGL and OpenGLES modes, the source code will be converted to GLSL.
- SHADER_SOURCE_LANGUAGE_GLSL - The shader source is in GLSL. There is currently no GLSL to HLSL converter, so this value should only be used for OpenGL and OpenGLES modes.
There are two ways to provide the shader source code. The first way is to use Source member. The second way is to provide a file path in FilePath member. Since the engine is entirely decoupled from the platform and the host file system is platform-dependent, the structure exposes pShaderSourceStreamFactory member that is intended to provide the engine access to the file system. If FilePath is provided, shader source factory must also be provided. If the shader source contains any #include directives, the source stream factory will also be used to load these files. The engine provides default implementation for every supported platform that should be sufficient in most cases. Custom implementation can be provided when needed.
When sampling a texture in a shader, the texture sampler was traditionally specified as separate object that was bound to the pipeline at run time or set as part of the texture object itself. However, in most cases it is known beforehand what kind of sampler will be used in the shader. Next-generation APIs expose new type of sampler called static sampler that can be initialized directly in the pipeline state. Diligent Engine exposes this functionality: when creating a shader, textures can be assigned static samplers. If static sampler is assigned, it will always be used instead of the one initialized in the texture shader resource view. To initialize static samplers, prepare an array of StaticSamplerDesc structures and initialize StaticSamplers and NumStaticSamplers members. Static samplers are more efficient and it is highly recommended to use them whenever possible. On older APIs, static samplers are emulated via generic sampler objects.
The following is an example of shader initialization:
ShaderCreationAttribs Attrs;
Attrs.Desc.Name = "MyPixelShader";
Attrs.FilePath = "MyShaderFile.fx";
Attrs.SearchDirectories = "shaders;shaders\\inc;";
Attrs.EntryPoint = "MyPixelShader";
Attrs.Desc.ShaderType = SHADER_TYPE_PIXEL;
Attrs.SourceLanguage = SHADER_SOURCE_LANGUAGE_HLSL;
BasicShaderSourceStreamFactory BasicSSSFactory(Attrs.SearchDirectories);
Attrs.pShaderSourceStreamFactory = &BasicSSSFactory;
ShaderVariableDesc ShaderVars[] =
{
{"g_StaticTexture", SHADER_VARIABLE_TYPE_STATIC},
{"g_MutableTexture", SHADER_VARIABLE_TYPE_MUTABLE},
{"g_DynamicTexture", SHADER_VARIABLE_TYPE_DYNAMIC}
};
Attrs.Desc.VariableDesc = ShaderVars;
Attrs.Desc.NumVariables = _countof(ShaderVars);
Attrs.Desc.DefaultVariableType = SHADER_VARIABLE_TYPE_STATIC;
StaticSamplerDesc StaticSampler;
StaticSampler.Desc.MinFilter = FILTER_TYPE_LINEAR;
StaticSampler.Desc.MagFilter = FILTER_TYPE_LINEAR;
StaticSampler.Desc.MipFilter = FILTER_TYPE_LINEAR;
StaticSampler.TextureName = "g_MutableTexture";
Attrs.Desc.NumStaticSamplers = 1;
Attrs.Desc.StaticSamplers = &StaticSampler;
ShaderMacroHelper Macros;
Macros.AddShaderMacro("USE_SHADOWS", 1);
Macros.AddShaderMacro("NUM_SHADOW_SAMPLES", 4);
Macros.Finalize();
Attrs.Macros = Macros;
RefCntAutoPtr<IShader> pShader;
m_pDevice->CreateShader( Attrs, &pShader );
Creating the Pipeline State Object
After all required shaders are created, the rest of the fields of the PipelineStateDesc structure provide depth-stencil, rasterizer, and blend state descriptions, the number and format of render targets, input layout format, etc. For instance, rasterizer state can be described as follows:
PipelineStateDesc PSODesc;
RasterizerStateDesc &RasterizerDesc = PSODesc.GraphicsPipeline.RasterizerDesc;
RasterizerDesc.FillMode = FILL_MODE_SOLID;
RasterizerDesc.CullMode = CULL_MODE_NONE;
RasterizerDesc.FrontCounterClockwise = True;
RasterizerDesc.ScissorEnable = True;
RasterizerDesc.AntialiasedLineEnable = False;Depth-stencil and blend states are defined in a similar fashion.
Another important thing that pipeline state object encompasses is the input layout description that defines how inputs to the vertex shader, which is the very first shader stage, should be read from the memory. Input layout may define several vertex streams that contain values of different formats and sizes:
// Define input layout
InputLayoutDesc &Layout = PSODesc.GraphicsPipeline.InputLayout;
LayoutElement TextLayoutElems[] =
{
LayoutElement( 0, 0, 3, VT_FLOAT32, False ),
LayoutElement( 1, 0, 4, VT_UINT8, True ),
LayoutElement( 2, 0, 2, VT_FLOAT32, False ),
};
Layout.LayoutElements = TextLayoutElems;
Layout.NumElements = _countof( TextLayoutElems );Finally, pipeline state defines primitive topology type. When all required members are initialized, a pipeline state object can be created by IRenderDevice::CreatePipelineState() method:
// Define shader and primitive topology
PSODesc.GraphicsPipeline.PrimitiveTopologyType = PRIMITIVE_TOPOLOGY_TYPE_TRIANGLE;
PSODesc.GraphicsPipeline.pVS = pVertexShader;
PSODesc.GraphicsPipeline.pPS = pPixelShader;
PSODesc.Name = "My pipeline state";
m_pDev->CreatePipelineState(PSODesc, &m_pPSO);When PSO object is bound to the pipeline, the engine invokes all API-specific commands to set all states specified by the object. In case of Direct3D12 this maps directly to setting the D3D12 PSO object. In case of Direct3D11, this involves setting individual state objects (such as rasterizer and blend states), shaders, input layout etc. In case of OpenGL, this requires a number of fine-grain state tweaking calls. Diligent Engine keeps track of currently bound states and only calls functions to update these states that have actually changed.
Binding Shader Resources
Direct3D11 and OpenGL utilize fine-grain resource binding models, where an application binds individual buffers and textures to certain shader or program resource binding slots. Direct3D12 uses a very different approach, where resource descriptors are grouped into tables, and an application can bind all resources in the table at once by setting the table in the command list. Resource binding model in Diligent Engine is designed to leverage this new method. It introduces a new object called shader resource binding that encapsulates all resource bindings required for all shaders in a certain pipeline state. It also introduces the classification of shader variables based on the frequency of expected change that helps the engine group them into tables under the hood:
- Static variables (SHADER_VARIABLE_TYPE_STATIC) are variables that are expected to be set only once. They may not be changed once a resource is bound to the variable. Such variables are intended to hold global constants such as camera attributes or global light attributes constant buffers.
- Mutable variables (SHADER_VARIABLE_TYPE_MUTABLE) define resources that are expected to change on a per-material frequency. Examples may include diffuse textures, normal maps etc.
- Dynamic variables (SHADER_VARIABLE_TYPE_DYNAMIC) are expected to change frequently and randomly.
Shader variable type must be specified during shader creation by populating an array of ShaderVariableDesc structures and initializing ShaderCreationAttribs::Desc::VariableDesc and ShaderCreationAttribs::Desc::NumVariables members (see example of shader creation above).
Static variables cannot be changed once a resource is bound to the variable. They are bound directly to the shader object. For instance, a shadow map texture is not expected to change after it is created, so it can be bound directly to the shader:
PixelShader->GetShaderVariable( "g_tex2DShadowMap" )->Set( pShadowMapSRV );Mutable and dynamic variables are bound via a new Shader Resource Binding object (SRB) that is created by the pipeline state (IPipelineState::CreateShaderResourceBinding()):
m_pPSO->CreateShaderResourceBinding(&m_pSRB);Note that an SRB is only compatible with the pipeline state it was created from. SRB object inherits all static bindings from shaders in the pipeline, but is not allowed to change them.
Mutable resources can only be set once for every instance of a shader resource binding. Such resources are intended to define specific material properties. For instance, a diffuse texture for a specific material is not expected to change once the material is defined and can be set right after the SRB object has been created:
m_pSRB->GetVariable(SHADER_TYPE_PIXEL, "tex2DDiffuse")->Set(pDiffuseTexSRV);In some cases it is necessary to bind a new resource to a variable every time a draw command is invoked. Such variables should be labeled as dynamic, which will allow setting them multiple times through the same SRB object:
m_pSRB->GetVariable(SHADER_TYPE_VERTEX, "cbRandomAttribs")->Set(pRandomAttrsCB);Under the hood, the engine pre-allocates descriptor tables for static and mutable resources when an SRB objcet is created. Space for dynamic resources is dynamically allocated at run time. Static and mutable resources are thus more efficient and should be used whenever possible.
As you can see, Diligent Engine does not expose low-level details of how resources are bound to shader variables. One reason for this is that these details are very different for various APIs. The other reason is that using low-level binding methods is extremely error-prone: it is very easy to forget to bind some resource, or bind incorrect resource such as bind a buffer to the variable that is in fact a texture, especially during shader development when everything changes fast. Diligent Engine instead relies on shader reflection system to automatically query the list of all shader variables. Grouping variables based on three types mentioned above allows the engine to create optimized layout and take heavy lifting of matching resources to API-specific resource location, register or descriptor in the table.
This post gives more details about the resource binding model in Diligent Engine.
Setting the Pipeline State and Committing Shader Resources
Before any draw or compute command can be invoked, the pipeline state needs to be bound to the context:
m_pContext->SetPipelineState(m_pPSO);Under the hood, the engine sets the internal PSO object in the command list or calls all the required native API functions to properly configure all pipeline stages.
The next step is to bind all required shader resources to the GPU pipeline, which is accomplished by IDeviceContext::CommitShaderResources() method:
m_pContext->CommitShaderResources(m_pSRB, COMMIT_SHADER_RESOURCES_FLAG_TRANSITION_RESOURCES);The method takes a pointer to the shader resource binding object and makes all resources the object holds available for the shaders. In the case of D3D12, this only requires setting appropriate descriptor tables in the command list. For older APIs, this typically requires setting all resources individually.
Next-generation APIs require the application to track the state of every resource and explicitly inform the system about all state transitions. For instance, if a texture was used as render target before, while the next draw command is going to use it as shader resource, a transition barrier needs to be executed. Diligent Engine does the heavy lifting of state tracking. When CommitShaderResources() method is called with COMMIT_SHADER_RESOURCES_FLAG_TRANSITION_RESOURCES flag, the engine commits and transitions resources to correct states at the same time. Note that transitioning resources does introduce some overhead. The engine tracks state of every resource and it will not issue the barrier if the state is already correct. But checking resource state is an overhead that can sometimes be avoided. The engine provides IDeviceContext::TransitionShaderResources() method that only transitions resources:
m_pContext->TransitionShaderResources(m_pPSO, m_pSRB);In some scenarios it is more efficient to transition resources once and then only commit them.
Invoking Draw Command
The final step is to set states that are not part of the PSO, such as render targets, vertex and index buffers. Diligent Engine uses Direct3D11-syle API that is translated to other native API calls under the hood:
ITextureView *pRTVs[] = {m_pRTV};
m_pContext->SetRenderTargets(_countof( pRTVs ), pRTVs, m_pDSV);
// Clear render target and depth buffer
const float zero[4] = {0, 0, 0, 0};
m_pContext->ClearRenderTarget(nullptr, zero);
m_pContext->ClearDepthStencil(nullptr, CLEAR_DEPTH_FLAG, 1.f);
// Set vertex and index buffers
IBuffer *buffer[] = {m_pVertexBuffer};
Uint32 offsets[] = {0};
Uint32 strides[] = {sizeof(MyVertex)};
m_pContext->SetVertexBuffers(0, 1, buffer, strides, offsets, SET_VERTEX_BUFFERS_FLAG_RESET);
m_pContext->SetIndexBuffer(m_pIndexBuffer, 0);Different native APIs use various set of function to execute draw commands depending on command details (if the command is indexed, instanced or both, what offsets in the source buffers are used etc.). For instance, there are 5 draw commands in Direct3D11 and more than 9 commands in OpenGL with something like glDrawElementsInstancedBaseVertexBaseInstance not uncommon. Diligent Engine hides all details with single IDeviceContext::Draw() method that takes takes DrawAttribs structure as an argument. The structure members define all attributes required to perform the command (primitive topology, number of vertices or indices, if draw call is indexed or not, if draw call is instanced or not, if draw call is indirect or not, etc.). For example:
DrawAttribs attrs;
attrs.IsIndexed = true;
attrs.IndexType = VT_UINT16;
attrs.NumIndices = 36;
attrs.Topology = PRIMITIVE_TOPOLOGY_TRIANGLE_LIST;
pContext->Draw(attrs);For compute commands, there is IDeviceContext::DispatchCompute() method that takes DispatchComputeAttribs structure that defines compute grid dimension.
Source Code
Full engine source code is available on GitHub and is free to use. The repository contains tutorials, sample applications, asteroids performance benchmark and an example Unity project that uses Diligent Engine in native plugin.
Atmospheric scattering sample demonstrates how Diligent Engine can be used to implement various rendering tasks: loading textures from files, using complex shaders, rendering to multiple render targets, using compute shaders and unordered access views, etc.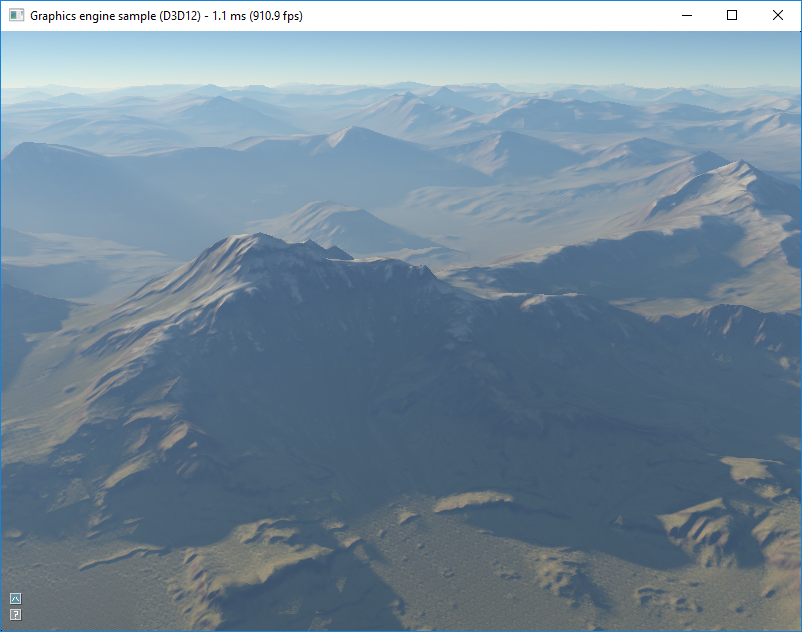
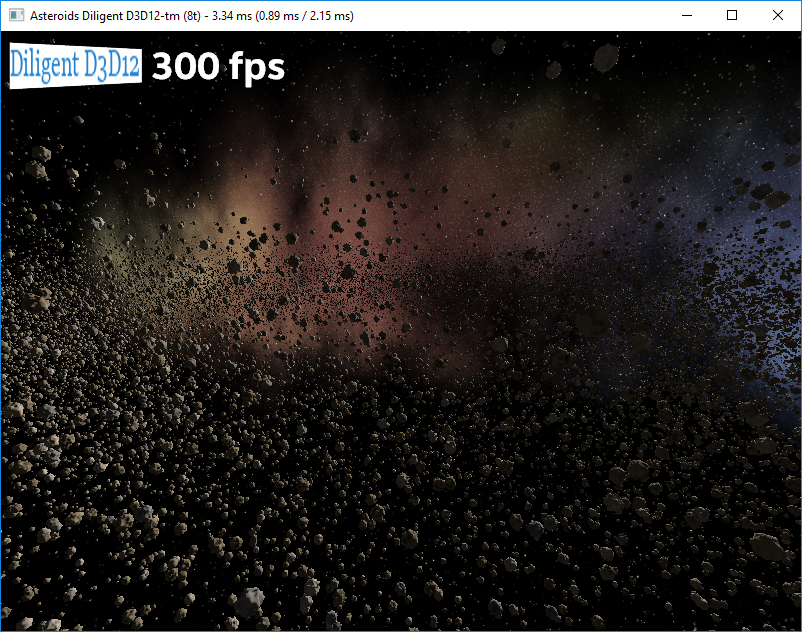
Asteroids performance benchmark is based on this demo developed by Intel. It renders 50,000 unique textured asteroids and allows comparing performance of Direct3D11 and Direct3D12 implementations. Every asteroid is a combination of one of 1000 unique meshes and one of 10 unique textures.
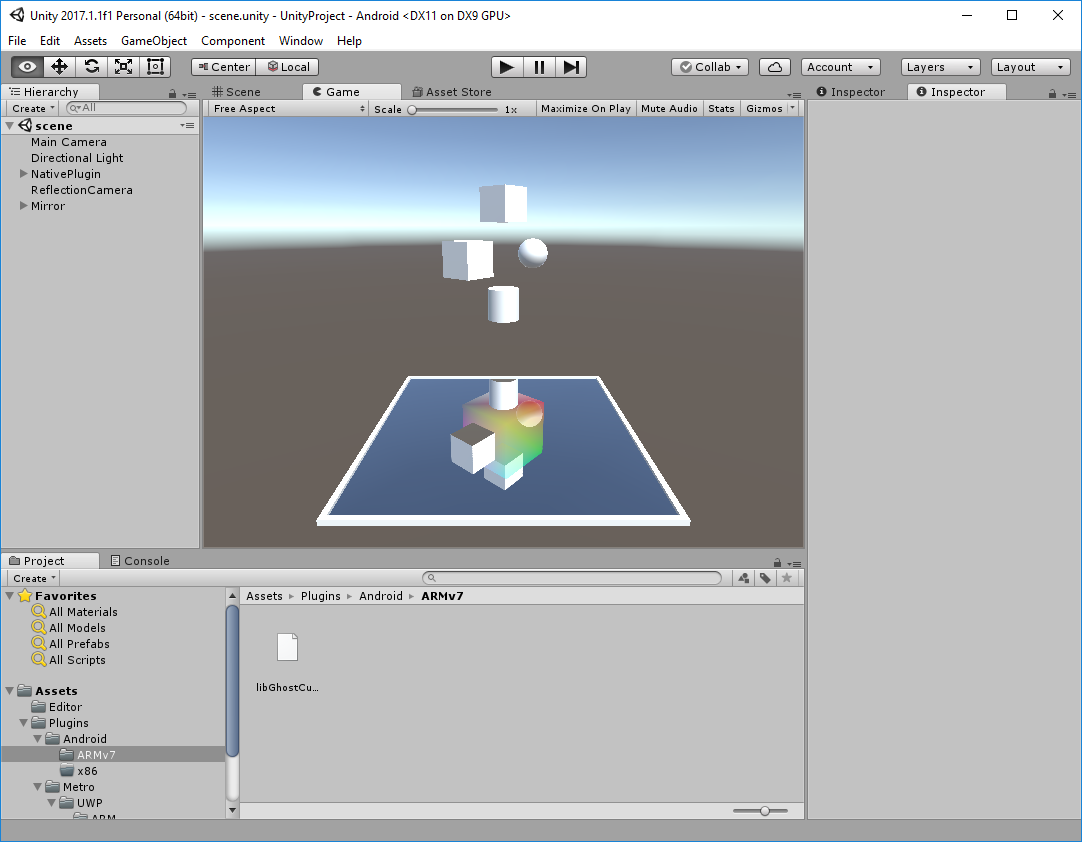
Finally, there is an example project that shows how Diligent Engine can be integrated with Unity.
Future Work
The engine is under active development. It currently supports Windows desktop, Universal Windows, Linux, Android, MacOS, and iOS platforms. Direct3D11, Direct3D12, OpenGL/GLES backends are now feature complete. Vulkan backend is coming next, and Metal backend is in the plan.




I think you just rename all DX11 interfaces and structures and this is not useful solution at all. For example, process of creation texture do not differ from case when is raw DX11 are used. All examples of usage of your API do not differ from usage of raw DX11. Rename it to examples of usage DX11 and no one will find difference.
Also with such model when you will try to add, for example, Vulkan API you will be forced to emulate DX11 interface and this will lead to bunch of unnecessary code.
You can not just rename all DX11 interfaces and say - Look every one I write brand new graphical API. That is not work at this way. If you really want to write something useful than you will need to add high level class like Buffer and Texture with do bunch of stuff like filling TextureDesc so all work with DX11 will be simplified.