
Last time, I had started working through Jamis Buck's Mazes for Programmers. I've made quite a lot of progress in the meantime, but haven't managed to keep up with posting about that progress. Today, we're going to work through the meat of Chapter 3, where we'll implement a simplified version of Di…
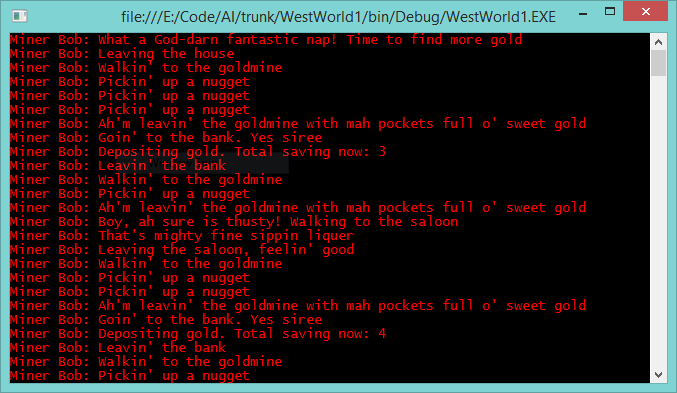
A few weeks back, I picked up a copy of James Buck's Mazes for Programmers: Code Your Own Twisty Little Passages. (The title is, of course, an homage to one of the original text adventure games, Colossal Cave Adventure, or Adventure for short, which featured a maze puzzle where every room was descr…
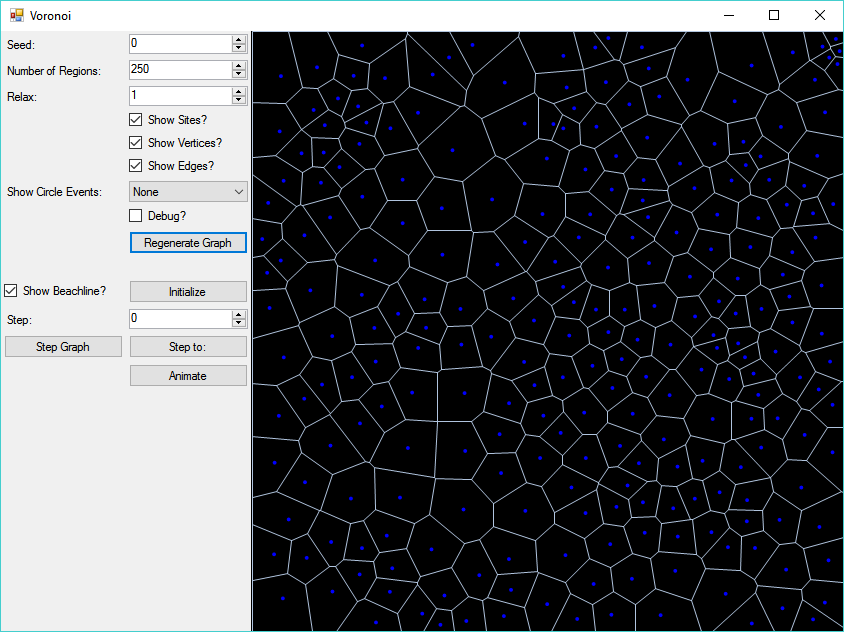
A little over two years ago, I first saw Amit Patel's article on Polygonal Map Generation, and thought it was incredibly cool. The use of Voronoi regions created a very nice, slightly irregular look, compared to grid-based terrains. At the time, I had just finished up working on my DX11 random terr…
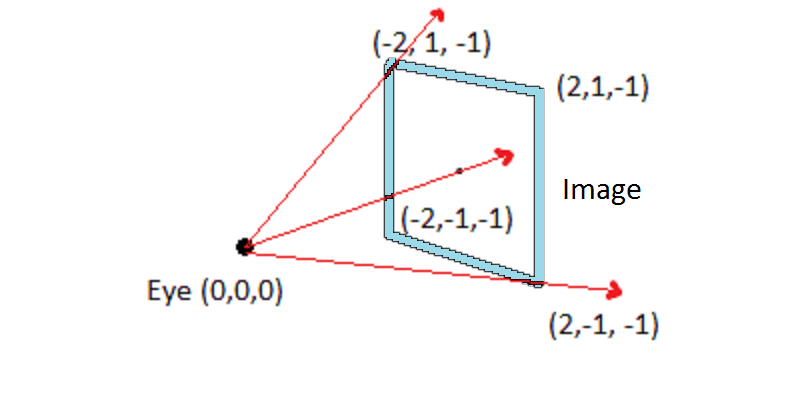
Alright, ready for the third installment of this ray tracing series? This time, we'll get some actual rays, and start tracing them through a scene. Our scene is still going to be empty, but we're starting to get somewhere. Although the book I'm working from is titled Ray Tracing in One Weekend, it'…

It's going to take me considerably longer than one weekend to build out a ray tracer...
Last time, I laid the groundwork to construct a PPM image and output a simple gradient image, like the one below.
This time around, I'm going to focus on building some useful abstractions that will make work goin…

Whew, it's been a while...
A few weeks ago, I happened across a new book by Peter Shirley, Ray Tracing in One Weekend. Longer ago than I like to remember, I took a computer graphics course in college, and the bulk of our project work revolved around writing a simple ray tracer in Java. It was one o…
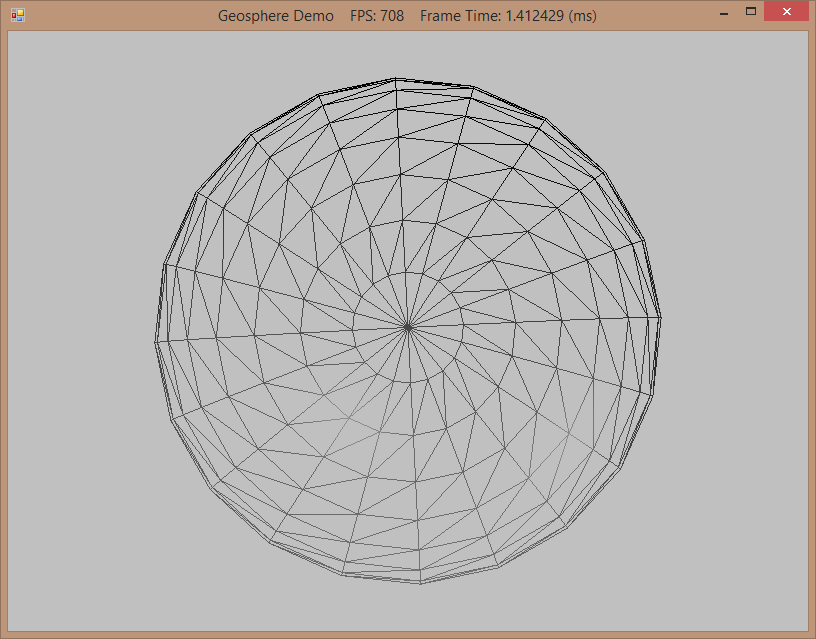
The biggest changes appear to be that the AssimpImporter/Exporter classes have been merged into a single AssimpContext class that can d…
Recently, I have been using OWIN a good deal for developing internal web applications. One of the chief benefits of this is that OWIN offers the ability to host its own HTTP server, which allows me to get out of the business of inst…
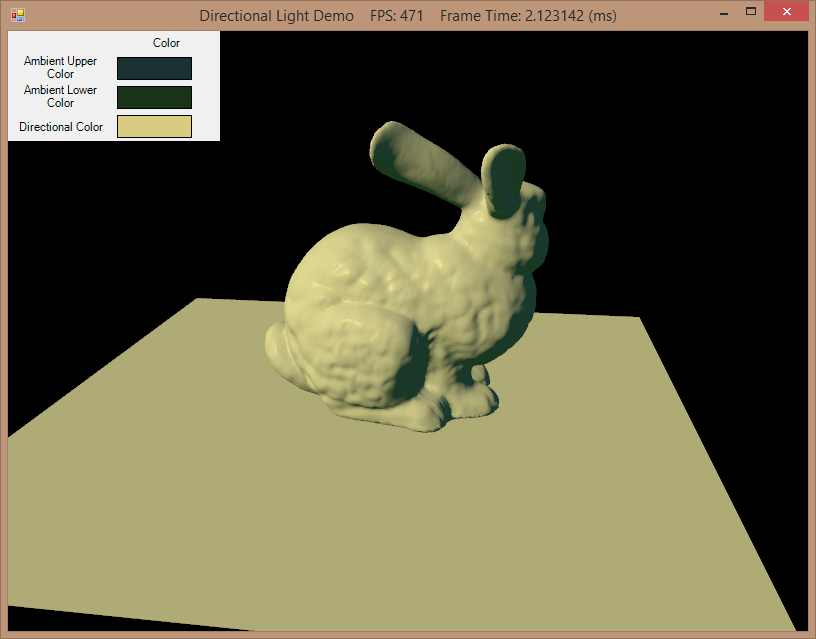
To recap, in case anyone is unfamiliar with the term, a directional light is a light wh…
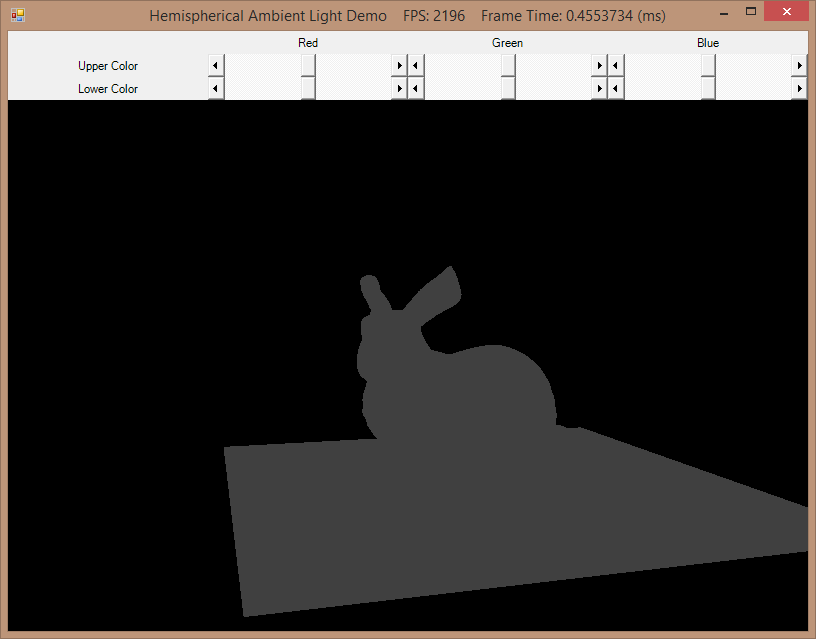
Another difficulty I had with this book wa…
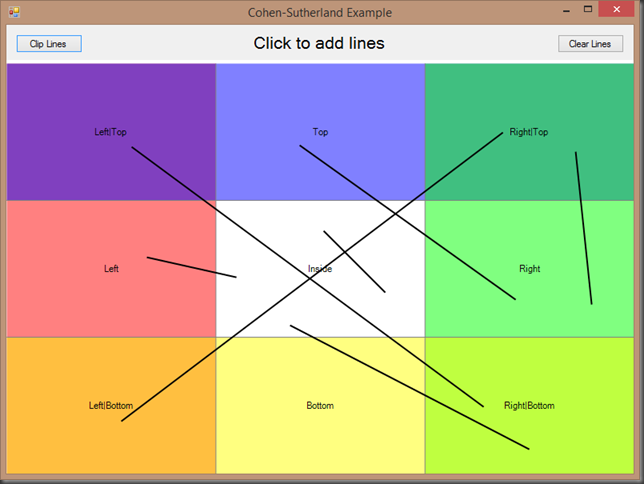
What I …
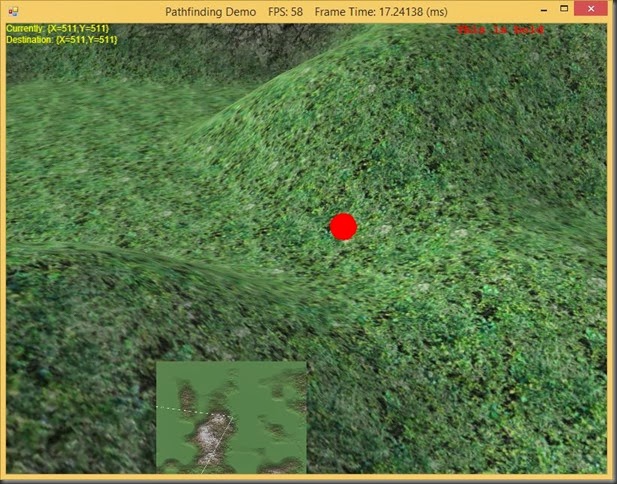
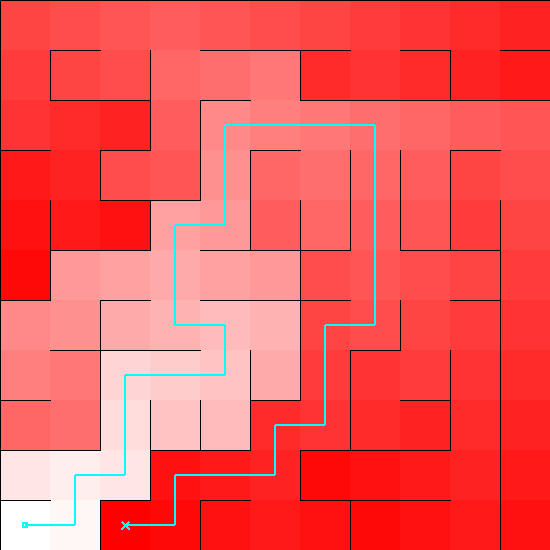
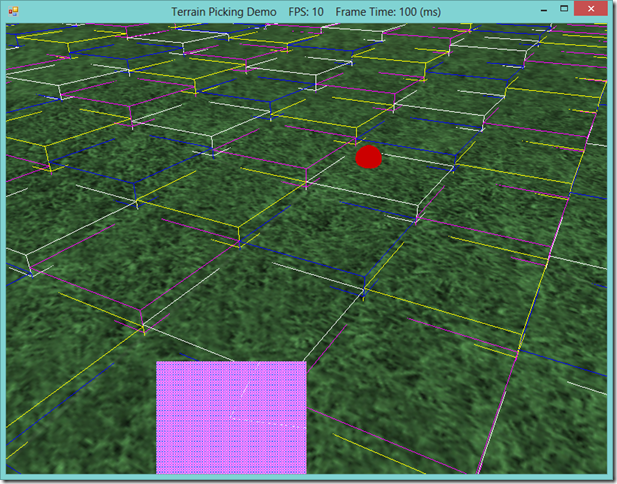
Watch the intrepid red blob wind its way through the mountain slopes!
Last time, we discussed the implementation of our A* pathfinding algorithm, as well as some commonly used heuristics for A*. Now we're going to put all of the …

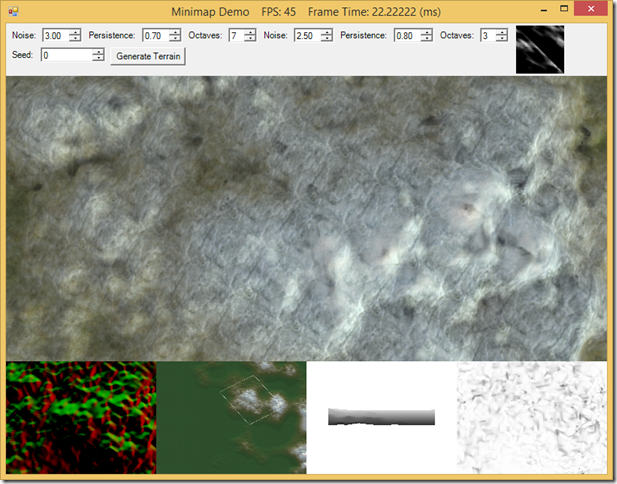
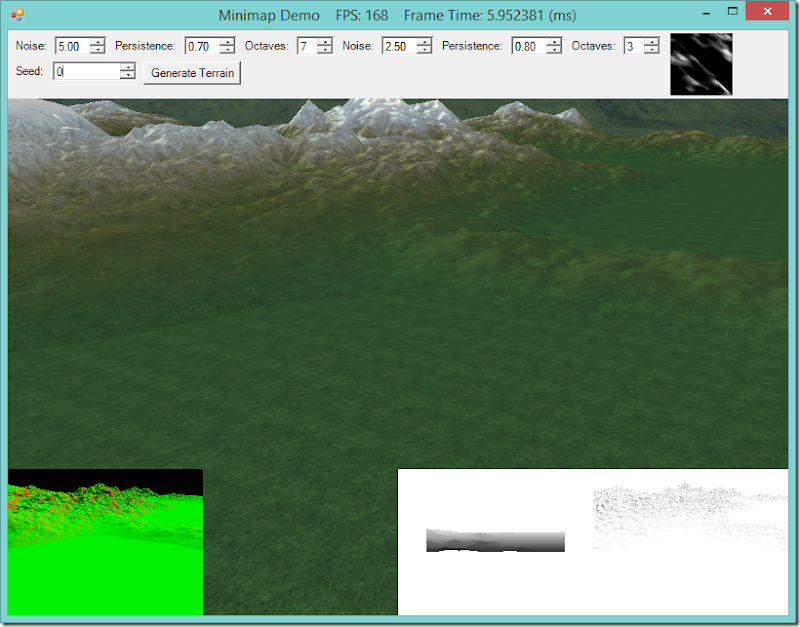
Minimaps are a common feature of many different types of games, especially those in which the game world is larger than the area the player can see on screen at once. Generally, a minimap allows the player to keep track of where they are in the larger game world, and in many games, par…
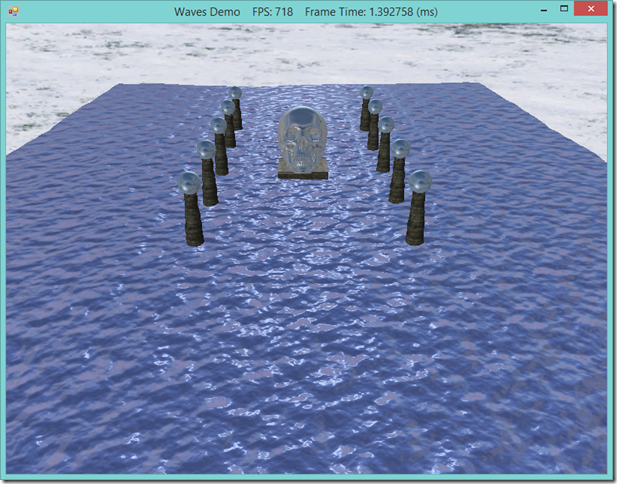
Quite a while back, I presented an example that rendered water waves by computing a wave equation and updating a polygonal mesh each frame. This method produced fairly nice graphical results, but it was very CPU-intensive, and relied on updating a vertex buffer every frame, so it had r…
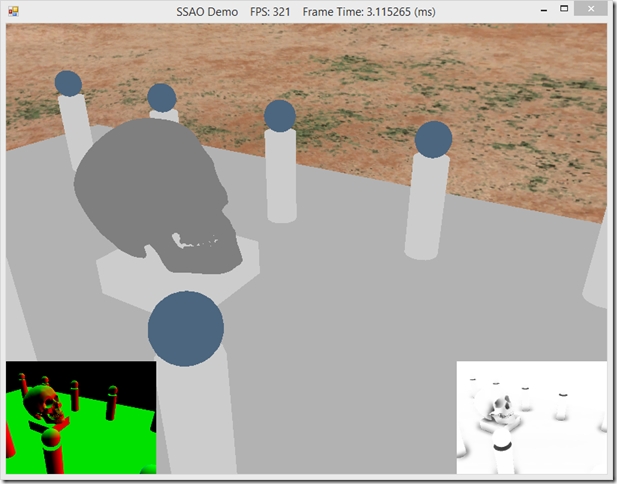
In real-time lighting applications, like games, we usually only calculate direct lighting, i.e. light that originates from a light source and hits an object directly. The Phong lighting model that we have been using thus far is an example of this; we only calculate the direct diffuse a…




