I just completed my research project my professor had given me to work on. I am very happy that it is finally done, and I feel I have learned quite a bit from the experience. This was the first project I had done that was outside of standard school assignments or for my own interest so I am proud to get that under my belt. I think I leveled up. 
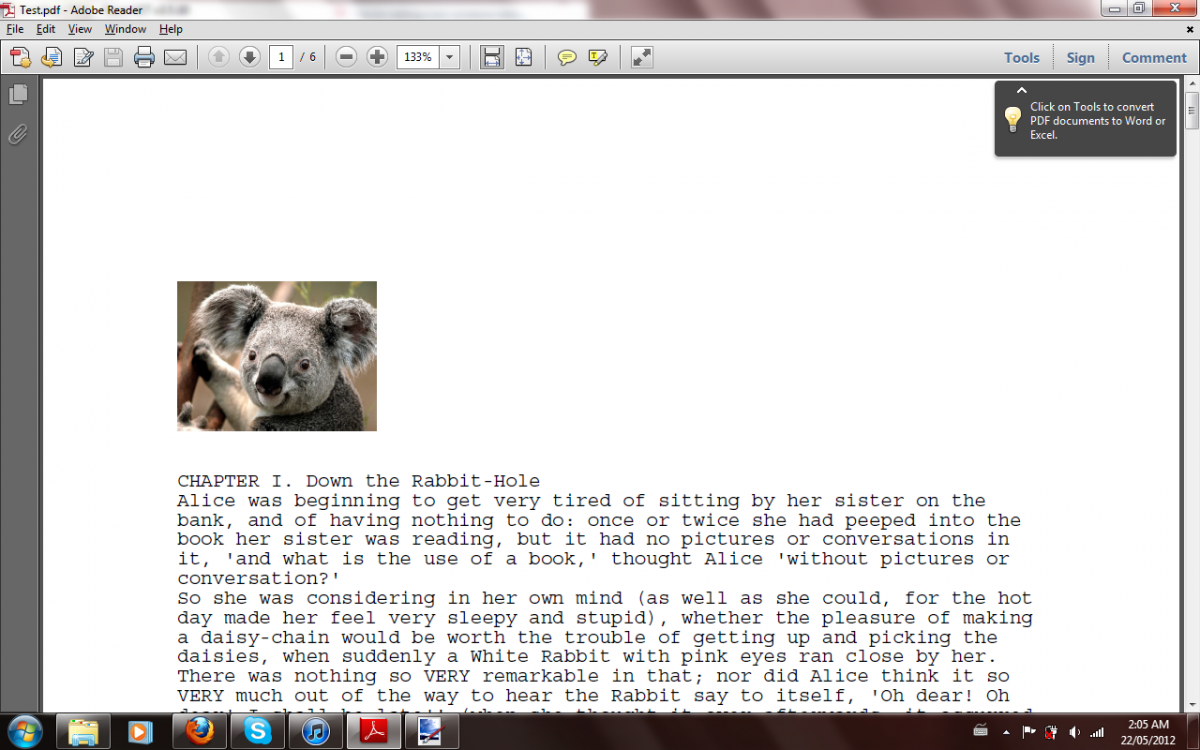
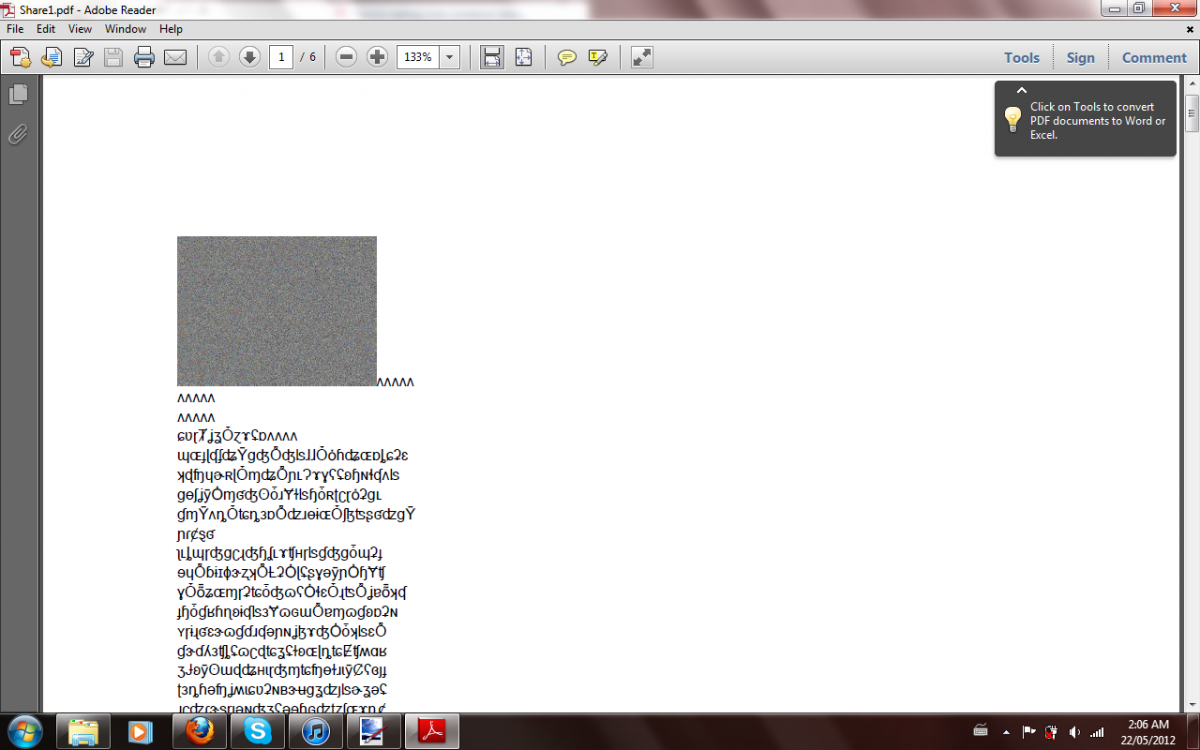
If you are curious as to what the encrypted data is like compared to the original here is a sample pdf file I made to use as a test, and a 'share' that was generated
from it: