To calculate UDP checksum a "pseudo header" is added to the UDP header. This includes:
IP Source Address 4 bytes
IP Destination Address 4 bytes
Protocol 2 bytes
UDP Length 2 bytes
The checksum is calculated over all the octets of the pseudo header, UDP header and data.
If the data contains an odd number of octets a pad, zero octet is added to the end of data.
The pseudo header and the pad are not transmitted with the packet.
[/quote]
I have to split the IP Source Address and IP Destination Address up into 2 words (2 16-bits), then add the Protocol and the U UDP length together to form a sum S, then do a 1's complement on the S, to get the checksum.
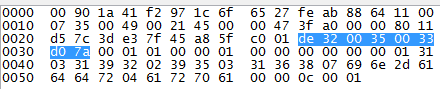
So, according to this packet, the highlighted part is the UDP header, split into 4 groups of 2 bytes. It represents in the following order, Source Port, Destination Port, Length, and Checksum, respectively.
According to the quote above, I should get the Source and Destination IP addresses, the protocol number and the UDP length field:
Source IP Address (in hex, located at address 0x0022): 3D E3 7F 45
Destination IP Address (located at address 0x0026): A8 5F C0 01
Protocol (located at address 0x001F): 11
UDP Length (located at address 0x002E): 00 33
Then I add those up in 16-bit, and I get this for the sum S: 0x25CC
Complementing S and it didn't match the checksum C (located at 0x0030): D0 7A
What have I done wrong? I mean, I don't understand what 16-bit segments should I split up, other than the UDP pseudo-header that was generated... I also noticed the protocol should be 2 bytes, yet all I got was 1 byte, so I don't know where to pad 1 byte full of zeroes at.
[Question] UDP Checksum Calculation Theory: Pseudo-Header and how to get the values for them.

Author
Given this information from most sources searched via Google:

The UDP checksum is handled automatically by the lower networking layers. Do you want to add an additional layer of checksumming on top?
Author
The UDP checksum is handled automatically by the lower networking layers. Do you want to add an additional layer of checksumming on top?
Of course not. I don't want myself to get over-obfuscated by it.
 But it would be nice enough for me to understand the math behind it, which unfortunately, I didn't get a nice grasp of it.
But it would be nice enough for me to understand the math behind it, which unfortunately, I didn't get a nice grasp of it.  All I need is the correct way of calculating the UDP checksum in the Transport Layer, so that way, I can create a simple protected 1-to-1 server for my homework. My professor thought I was working too hard over this, but I just loved to give myself a little bit of challenge.
All I need is the correct way of calculating the UDP checksum in the Transport Layer, so that way, I can create a simple protected 1-to-1 server for my homework. My professor thought I was working too hard over this, but I just loved to give myself a little bit of challenge.

[quote name='rip-off' timestamp='1305725583' post='4812506']
The UDP checksum is handled automatically by the lower networking layers. Do you want to add an additional layer of checksumming on top?
Of course not. I don't want myself to get over-obfuscated by it.
But it would be nice enough for me to understand the math behind it, which unfortunately, I didn't get a nice grasp of it. All I need is the correct way of calculating the UDP checksum in the Transport Layer, so that way, I can create a simple protected 1-to-1 server for my homework. My professor thought I was working too hard over this, but I just loved to give myself a little bit of challenge.[/quote]
First, how are you generating these packets? Using raw IP sockets?
Second, all network operations are done in BIG ENDIAN mode. This means that each 16-bit word has the big byte first. This means that "protocol" is a zero followed by the IP protocol byte. This is well illustrated in the Wikipedia article on UDP datagrams:
http://en.wikipedia.org/wiki/User_Datagram_Protocol
Meanwhile, the padding always goes at the end, so the last byte is actually the high byte of the last word in this case!
I found some C code to calculate UDP checksums using a two-second Google search. You may want to read it for reference:
http://www.netfor2.com/udpsum.htm
Although, it being free on the internet from some random guy, it may or may not be authoritative :-)
Author
First, how are you generating these packets? Using raw IP sockets?
Second, all network operations are done in BIG ENDIAN mode. This means that each 16-bit word has the big byte first. This means that "protocol" is a zero followed by the IP protocol byte. This is well illustrated in the Wikipedia article on UDP datagrams:
http://en.wikipedia....tagram_Protocol
Meanwhile, the padding always goes at the end, so the last byte is actually the high byte of the last word in this case!
I found some C code to calculate UDP checksums using a two-second Google search. You may want to read it for reference:
http://www.netfor2.com/udpsum.htm
Although, it being free on the internet from some random guy, it may or may not be authoritative :-)
I generate these packets from Wireshark and using the command prompt to call "nslookup". I don't use raw IP sockets. I don't understand the C code, because I don't understand the theory of finding out the walkthrough to how to calculate the checksum, as mentioned below. This is why I ask such question to everyone, because, reading the codes sometimes still confuses me, without no knowledge prior to computer networking.
Again, back to the theory, you have a pseudo-header. Given 4 bytes for the source IP address, 4 bytes for the destination IP address, 2 byte for the protocol, and 2 bytes for the UDP packet's length. The checksum is calculated over all the octets of the pseudo header, UDP header and data. [color="#ff0000"]Tell me if I'm wrong on this one.
1. You split the entire pseudo-header into groups of 1-byte long units, with the remaining spaces replaced with zeroes. Then you add them up. (True/False)
2. After obtaining the sum of that, you also need to split the UDP header up into groups of 1-byte long units, then add all of them to the sum. (True/False)
3. After obtaining the newer sum from above, you also need to split up all of the data into 1-byte long units, then add all of the octets up into the sum. (True/False)
4. Then you do a 1's complement on the sum, and you have obtain the checksum for the UDP.
Please check.

The definitive source is the RFC for UDP.
From skimming that, you seem to be totally incorrect, apart from step 4. The header is "chunked" into groups of 16 bits, and there is only a single zero byte added to the data in the case where there aren't enough 16 bit groups (i.e. an odd sized packet).
From skimming that, you seem to be totally incorrect, apart from step 4. The header is "chunked" into groups of 16 bits, and there is only a single zero byte added to the data in the case where there aren't enough 16 bit groups (i.e. an odd sized packet).
Author
The definitive source is the RFC for UDP.
From skimming that, you seem to be totally incorrect, apart from step 4. The header is "chunked" into groups of 16 bits, and there is only a single zero byte added to the data in the case where there aren't enough 16 bit groups (i.e. an odd sized packet).
Exactly. I always see this graph show below:
[source lang="cpp"][font="Arial"]
[font="Courier New"]// 0 7 8 15 16 23 24 31
// +--------+--------+--------+--------+
// | source address |
// +--------+--------+--------+--------+
// | destination address |
// +--------+--------+--------+--------+
// | zero |protocol| UDP length |
// +--------+--------+--------+--------+
[/font]
[/font][/source]
I don't know how to add these up. I could never understand what the RFC meant by "obtaining the sum of the pseudo header ([color="#0000ff"]shown above), the UDP header ([color="#00ff00"]the entire UDP header or parts of it?), and the data ([color="#ff0000"]again, all of it??)". I did the cacluation and it wasn't correct when I complement it.
Do I just do:
[color="#4169e1"]NOT(source address + destination address + ([zero] [protocol] [UDP length]))
to get the checksum?
Or do you split them into 2 octets:
[color="#4169e1"](First half of the source address) + (Second half of the source address) + (First half of the destination address) + (Second half of the destination address) + ([zeroes] and [protocol] blocks together) + (UDP length)?
[color=#1C2837][size=2]reading the codes sometimes still confuses me, without no knowledge prior to computer networking
[color=#1C2837][size=2]
To put it another way: If this was a "file" rather than a "network packet," the algorithm and code would be the same, so if you can't read the C code, then you also can't read C code that calculates checksums for files. And if this was a "memory stream" instead of a "network packet," then you can't read C code that calculates checksums for memory streams.
If you don't understand the C code, which is just plain C code -- it sounds as if you need to improve in C programming! Given that the difference between bytes and 16-bit (half)words is one of the fundamentals of C programming, and memory layout and data alignment in general is highly important to any real C program, you should understand C enough to read that snippet before you start looking at systems programming topics (like network programming, or device drivers, or file formats, or whatever).
Author
To put it another way: If this was a "file" rather than a "network packet," the algorithm and code would be the same, so if you can't read the C code, then you also can't read C code that calculates checksums for files. And if this was a "memory stream" instead of a "network packet," then you can't read C code that calculates checksums for memory streams.
If you don't understand the C code, which is just plain C code -- it sounds as if you need to improve in C programming! Given that the difference between bytes and 16-bit (half)words is one of the fundamentals of C programming, and memory layout and data alignment in general is highly important to any real C program, you should understand C enough to read that snippet before you start looking at systems programming topics (like network programming, or device drivers, or file formats, or whatever).
So, where do we start adding 16-bit words from in a packet? (What hexadecimal address should I start reading the data, and in what order of addition should I start off with?)
It's not like I don't know C programming, it's the theory behind the calculation. I'm interested in the theory of doing the UDP checksum, and only using raw datagram packets to calculate the checksums by hand. I dislike reading the C code purely because it doesn't tell me where to start reading the UDP packet, and at what address in the packet.
It's like you're confusing me with someone who doesn't know how to read C programming code, which is really a bad assumption, since throughout the whole thread, I was asking how to obtain the checksum by hand, by theory, by mathematical means, instead of relying on programming and obtaining the results from there. And I didn't say that I wanted to program it out.
[color="#ff0000"]I feel like I'm being misunderstood. I wanted to clear this out, I don't want the code, I want the step-by-step instructions on how to compute the checksum by hand, when all you've got is a Wireshark UDP packet that you've gotten from using "nslookup" in the command prompt.
[color="#ff0000"]I feel like I'm being misunderstood. I wanted to clear this out, I don't want the code, I want the step-by-step instructions on how to compute the checksum by hand, when all you've got is a Wireshark UDP packet that you've gotten from using "nslookup" in the command prompt.
And I pointed you at C source code that does exactly that. If you feel that you cannot translate C source code to step-by-step instructions, then I don't know what to say. C source code is explicitly and by necessity a step-by-step instruction for how to do it.
I also pointed at the Wikipedia article that explains the process in very clear detail, and me and others have mentioned the most obvious causes of mis-calculation (byte order, 16-bit words, how to treat the padding byte).
If, given these instructions, you cannot calculate a UDP checksum, then I don't know what to do. The code is already written for you! The algorithm is described in detail! The typical gotchas are called out already!
This topic is closed to new replies.
Advertisement
Popular Topics


Advertisement

