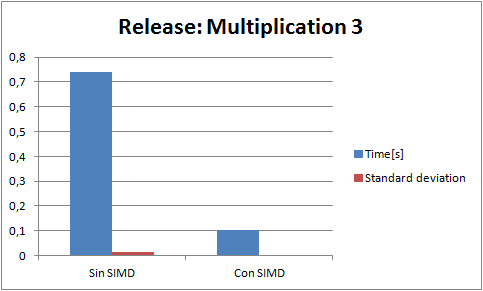
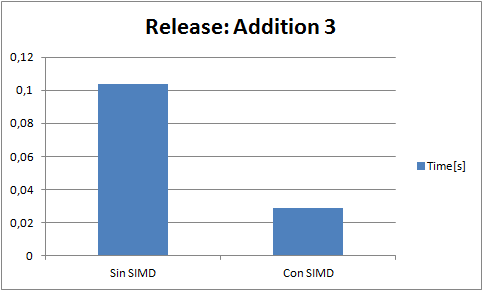
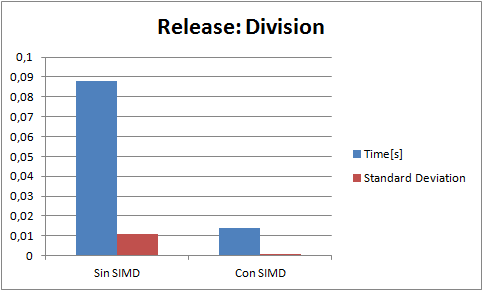
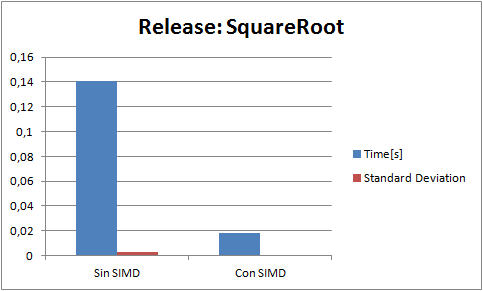
I perform a few tests. Each test consist of 5000000 operations of its kind(for example only divisions). And a result is the analisis of 20 tests(60 in the case of the addition because it had higer standard deviation Gods knows why). Every test is run in release with speed optimizations, and Enable Enhaced Instruction Set to Not Set (the only diference that it makes is that makes my code that runs in the fpu slower).The blue bar is the average time(in seconds) of a test, and the red bar is the standard deviation. Here are the results ive got:
(NOTE: "Con SIMD" means test made with SIMD and "Sin SIMD" means test made without SIMD, ie fpu)
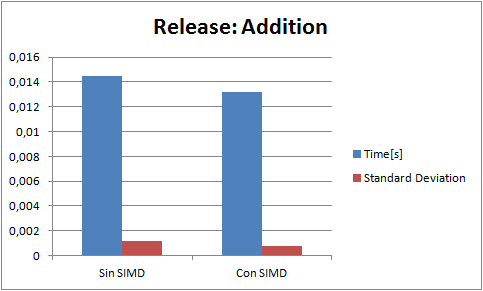
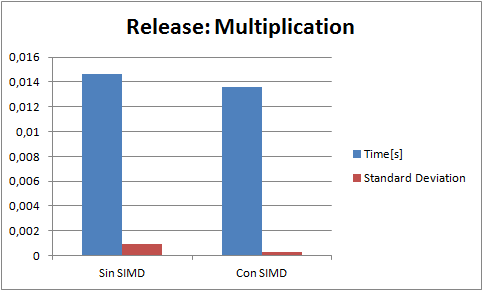
The code for example to make an addition is:
---------- Vector4.h --------------
#ifdef SIMD_EXTENSION
class Vector4
{
public:
__declspec(align(16)) union
{
__m128 m_xyzw;
struct
{
float m_x, m_y, m_z, m_w;
};
};
//This union is not probably a good idea... What do you think?
//Anyway i never get m_x, m_y, m_z, m_w in this test
.....
inline Vector4 operator+(const Vector4 &B) const
{
return Vector4( _mm_add_ps(m_xyzw, B.m_xyzw) );
}
....
#else
class Vector4
{
public:
float m_x, m_y, m_z, m_w;
......
inline Vector4 operator+(const Vector4 &B) const
{
return Vector4( m_x+B.m_x, m_y+B.m_y, m_z+B.m_z, m_w+B.m_w );
}
.....
#endif
A simplified example of a call of a addition operation inside the test would be:
Vector4* data = (Vector4*)_aligned_malloc(iterations*sizeof(Vector4), __alignof(Vector4));//if not properly aligned everything is going to hell
srand(static_cast<unsigned int>(time(NULL)));
for(unsigned int i=0; i < iterations ;++i)
data = Vector4(static_cast<float>(rand()%100), static_cast<float>(rand()%100), static_cast<float>(rand()%100), static_cast<float>(rand()%100));
...... later inside a test
data = data +data[i+1];
.... other operations of addition
Here is my code. There are projects for Visual Studio 2008 and 2010.
Code
The examples i have seen in the web that show times always use division or squareroot... i dont know if intentionaly or what. For example:
http://software.inte...u-acceleration/
http://supercomputin...se-programming/
http://www.codeproje...s/sseintro.aspx