
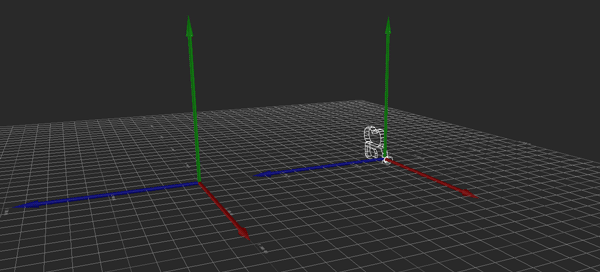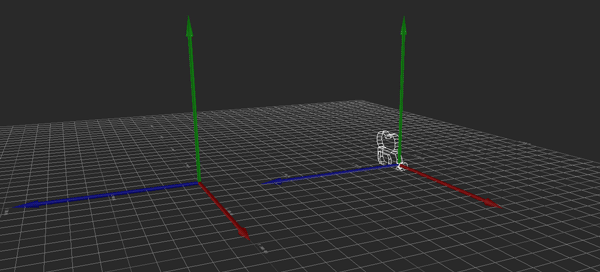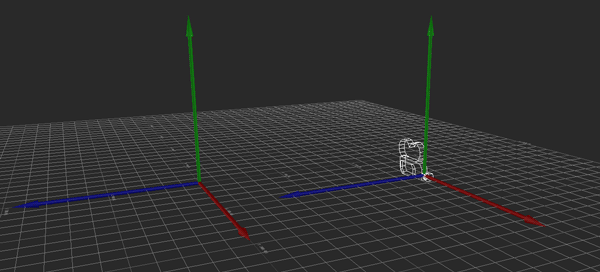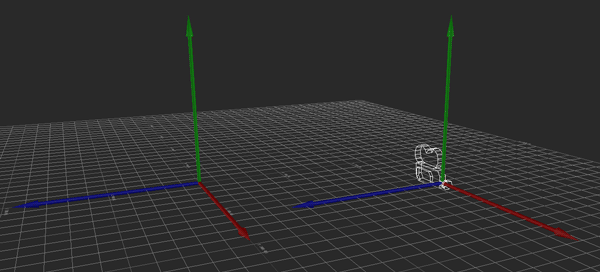
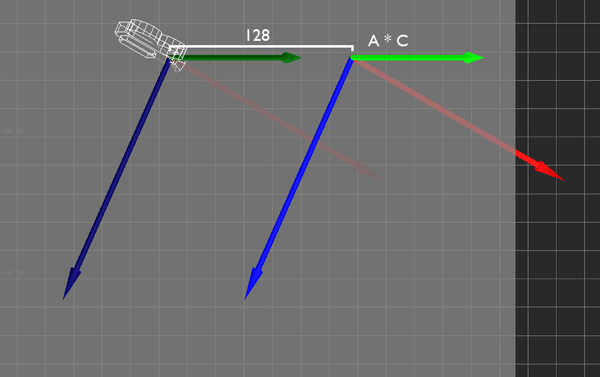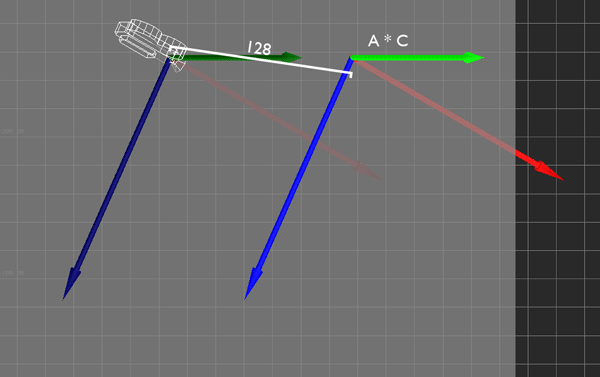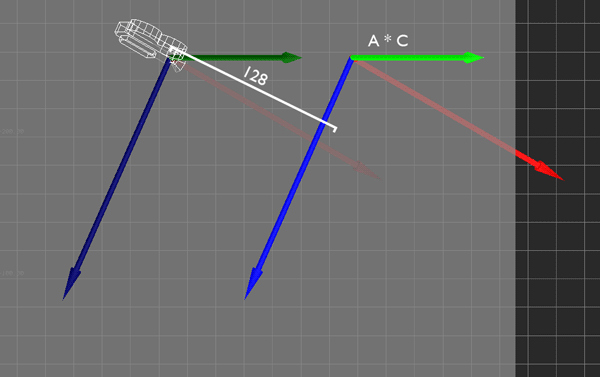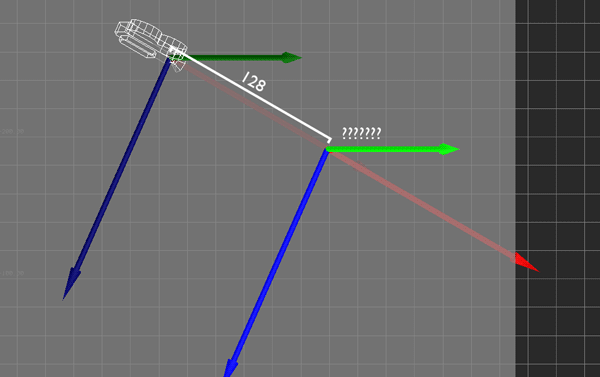
Ordinarily, this movement is local to the camera. If I push the stick such that I want to move 128 units forward and 64 to the right, the camera moves by 128 units along its forward (X) vector and by 64 along its right (Z) vector.
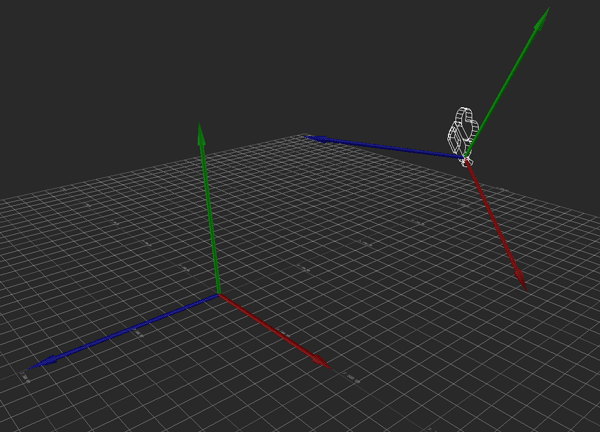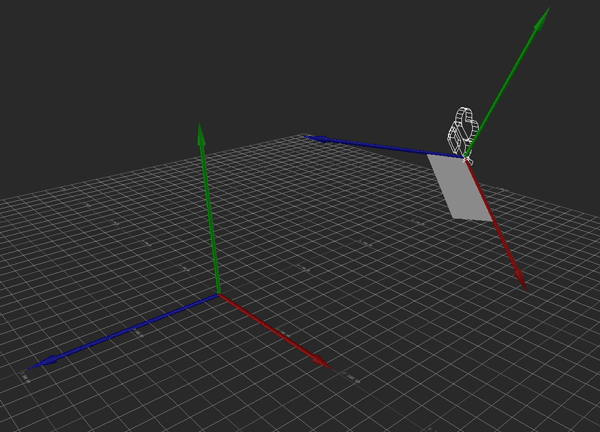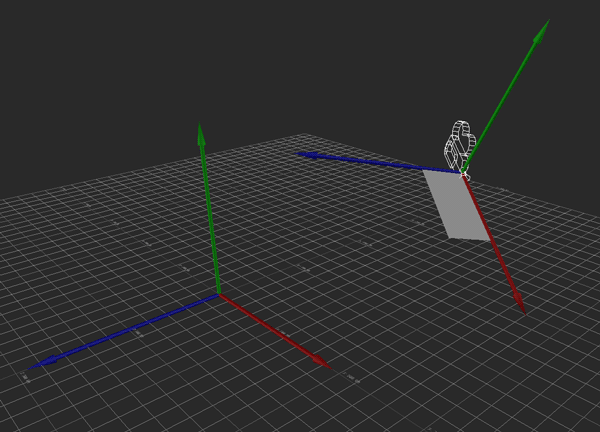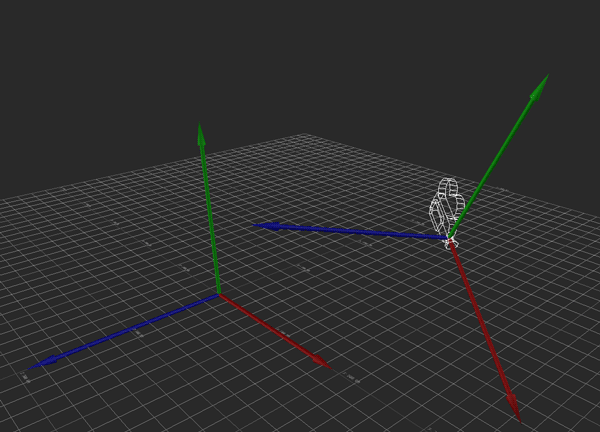
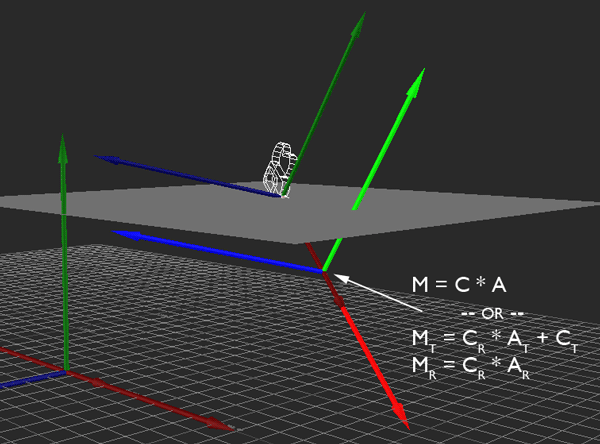
I'm performing this transformation with some simple matrix multiplication. I simply multiply the camera's transformation matrix C by the desired movement A to get the new camera position. This is all fine and dandy, and because I'm using matrices, this covers me for whatever translation, rotation, and scale the camera might have.

So in local movement mode, that's how the desired change in position, as indicated by joystick input, is interpreted and applied as camera movement.
However, I also want there to be another mode for camera movement, and this is where I need some help. In this mode, moving forward-back or right-left does so without respect to pitch or roll (i.e., parallel to the ground (XZ), without changing altitude (Y)), and moving up-down does so in the direction of global Y (straight up and down, without respect to rotation). However, I still want to preserve the original heading of the camera, so that it's still moving forward, in some sense.
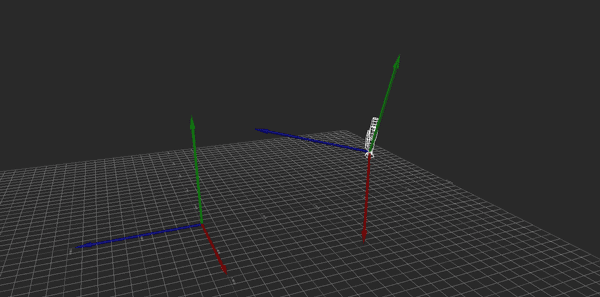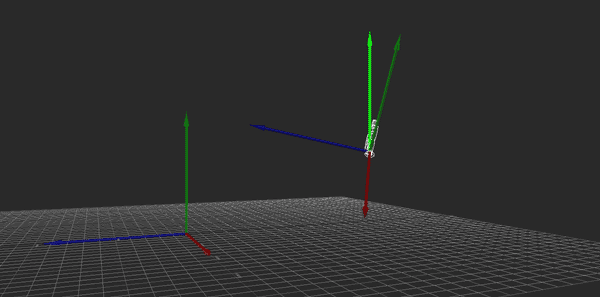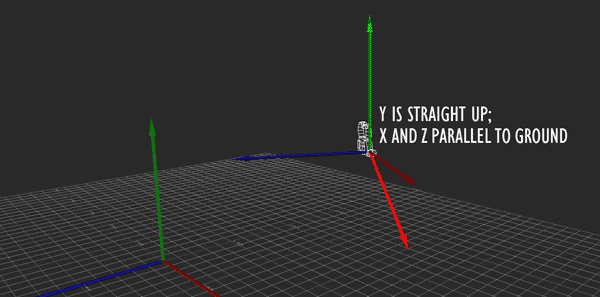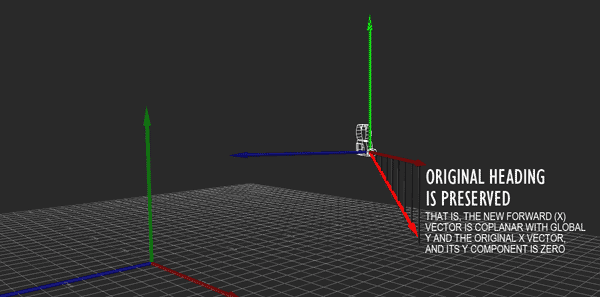
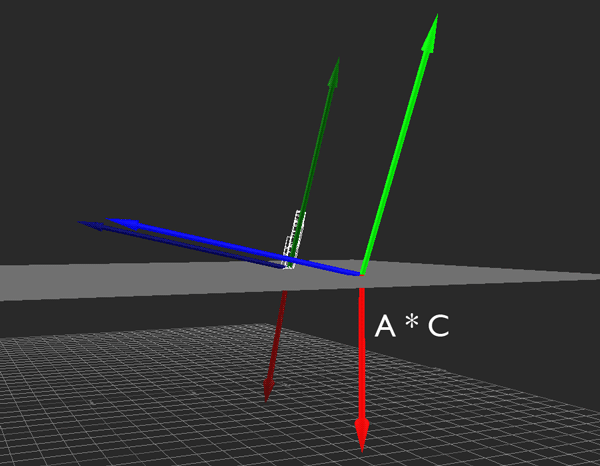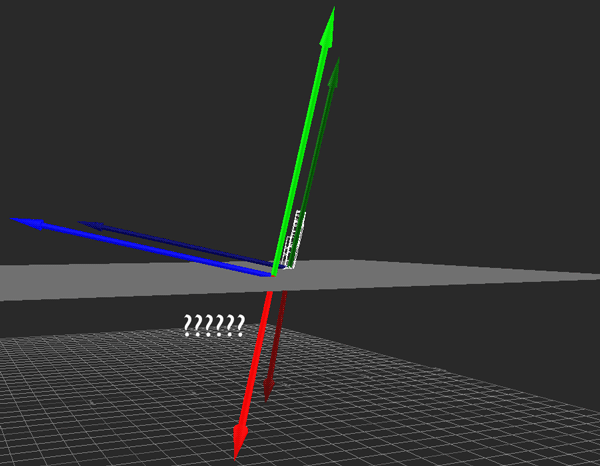
Hopefully the above image explains it (If it happens to be stopped, you may need to reload it). Conceptually, what I want to do is rotate the camera so that its local Y axis is aligned with global Y, its local X and Z are parallel to the ground (global XZ), and its yaw (i.e., its rotation about the Y axis) matches the heading it originally had. That way, I can apply the movement just as before, then restore the original rotation.

Unfortunately, I'm profoundly uneducated when it comes to matrix math. I can think of a few ways to achieve what I'm looking for (using cross products to construct the new transformation matrix, directly altering Y position after local-space movement is calculated), but I haven't come up with a solution that meets all the criteria I need and also fits neatly into the whole transformation matrix paradigm. If you can think of one, I would dearly love to hear it.
Thanks!

 it seems me that you use column vectors, and so do I in the following.
it seems me that you use column vectors, and so do I in the following.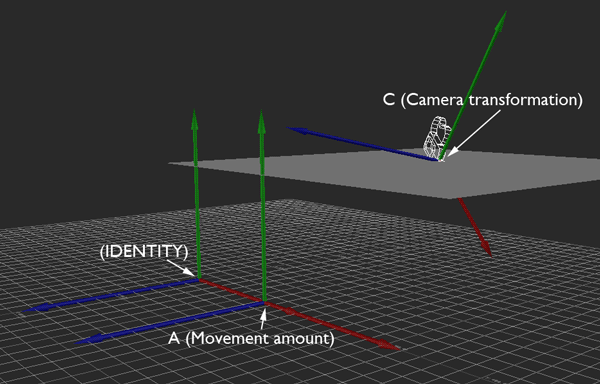

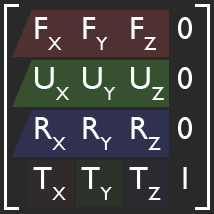
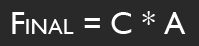


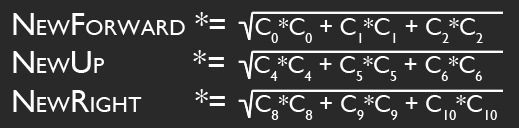
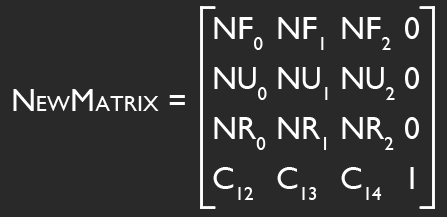
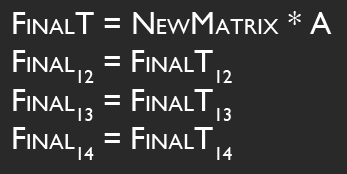



{kind=link}