
-detail on a per-pixel level (naturally because you can't have more than that!)
-no wasted information (anything that is outside the view frustum or covered by another object will never be calculated)
If you meet these two conditions, you should have exactly one vertex for every screen pixel.
In theory this would mean the rendering would take roughly the same amount of time regardless of your view point or how many objects you are rendering.
So I was curious if this has been done? I'm certain it can be done, just not yet in realtime.
Also I'd like to post my idea on how it could be done. Keep in mind I'm no expert and this is just a general idea.
And if anything is incorrect please forgive me.
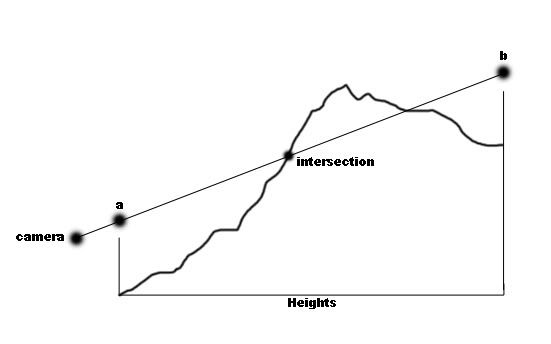
You start by cycling through each pixel on the screen. For each pixel [x, y] you find the point in 3D space that lies within the near clipping plane and matches the pixel's coordinates when projected into 2D. We will call this point "a". There are an infinite number of 3D points that match up with a given screen pixel, but only one that is in the near clipping plane.
The 3D point inside the near clipping plane that matches the 2D pixel will be your starting point.

From here there is a simple way to define all 3D points within the camera's frustum that would match up in 2D screen space with the pixel you are currently on.
You have a starting point, now you need a direction to go in and a distance to travel to come up with a line segment that contains all possible points that match the pixel you are on.
The direction to go in is simply Normalize(a - CamPosition)
The distance to travel = far clipping plane - near clipping plane.
Now you can find the 3D point on the far clipping plane that corresponds to the 2D pixel you are on. We will call this point "b"
b = a + Direction * (farPlane - nearPlane)
Now draw a line from a to b and you pass through all points in the frustum that match the 2D pixel.
Somewhere along this line segment is the 3D point you need for calculating the current pixel.
So basically you have to find the first intersection of line segment (a, b) and the geometry, starting with a and moving towards b.
This is pretty tricky, but I have one idea on how to do it if you are rendering a height field or using a noise function.
You make a point "p" and start it out at a and move in a certain interval at a time towards b (similar to "ray marching"). You will start out using a large interval.
Every time you move p forward towards b, you check the height at that x and z of the point p. Something like height = getHeight(p.X, p.Z);
If the height returned is larger than the height of p, then you have found an intersection, else keep moving forward.
Once you find an intersection, set p back one jump and decrease the interval you move at and start again from there, marching towards b and looking for an intersection.
Repeat this a few times, depending on how much precision you want in finding the intersection of the line segment and the geometry.
Now you will need a normal for this vertex, but this form of rendering doesn't use triangles or any sort of polygons at all.
There are many solutions for this, and you end up with a lot of flexibility for how much precision you want your normals to have.
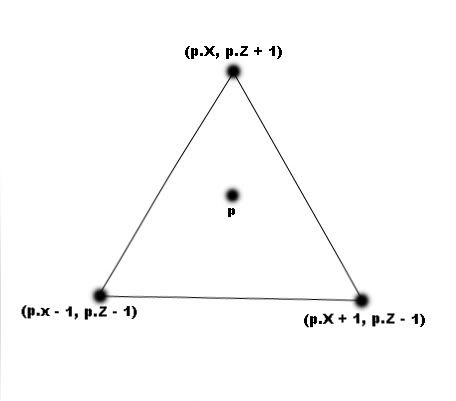
Here is a quick and simple solution though - Create a triangle centered around the vertex that needs a normal. Get the height of the 3 vertices of this triangle and then calculate its normal.
With this type of algorithm, there would be no poly budget or any problems with creating curves.
The distribution of vertices would always be uniform thoughout the screen. There are too many advantages to name.
It certainly sounds too slow for now, but I can see it being possible in the future because each pixel can be calculated independently of every other pixel, making it ideal for parallel computing.
I think if you had a GPU that could work on every pixel simultaneously you would be set.









{kind=link}
{kind=link}