
Check the post further down for another question on GeoClipMaps.
I am in the process of implementing GeoClipMaps (for the second time, first attempt never finished), and I have been looking through the online resources on terrain rendering to see if something new has popped up since my last try.
So i found this post http://electronicmeteor.wordpress.com/2013/02/10/big-progress-on-geo-clipmaps-and-terrain/, to cut things short - in the post the author explains that instead of doing it like in the GPU Gems article, where they split up each level of geometry into several parts allowing just a few vertex buffers to be allocated for the entire terrain, the author instead pre-allocates a mesh for each clip level, see screenshots:
GPU Gems:

Blog Author:
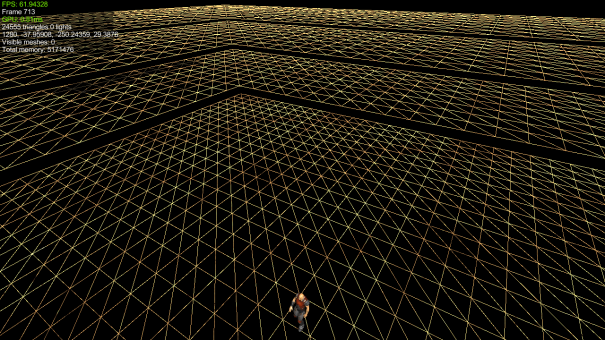
The above screenshot from the blog is a work in progress and still has gaps, etc, but I am thinking about the pros/cons of these approaches. The approach in the blog seems a lot easier to build, but I am thinking there could be some major drawbacks to doing it like this (memory requirements, needing one separate vertex buffer per clip level, etc).
Anyone willing to weigh on this?




