
I have recently read T-machine's Entity Component System (ECS) data structure. (link)
Its "best" version (4th iteration) can be summarized into a single image (copy from T-machine's web) :-
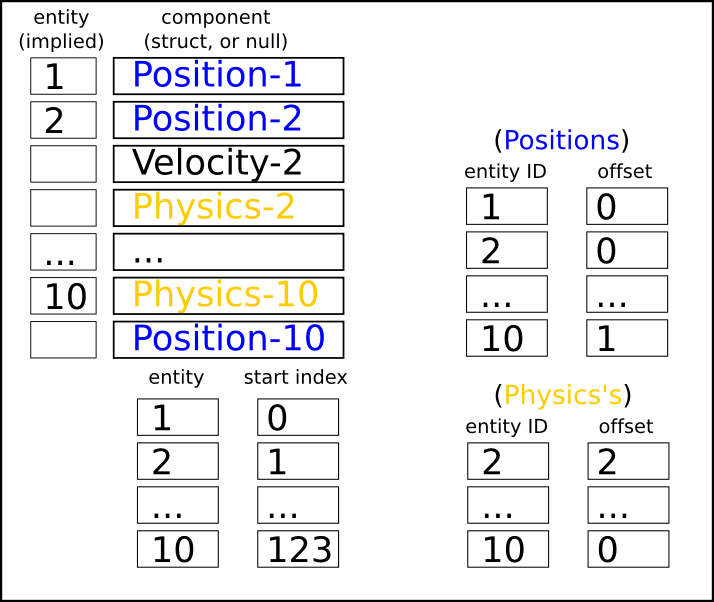
This approach also appears in a VDO
" rel="external">There are many people (including me) believe that the above approach lacks data locality, because Position-1,Position-2,Position-3, ... are not stored in a contiguous array.
However, many attempts failed to elegantly make it contiguous. (e.g. stackoverflow's link)
- I also realized that, to make it contiguous, the cost of query Entity<-->Component is unavoidably significantly higher. (I profiled)
I would like to hear that ....
- Is such mega-array (T-machine's 4th) generally better (performance-wise) than storing each type component to its own contiguous array? (like http://www.randygaul.net/2013/05/20/component-based-engine-design/ ) ?
- My references (those links) are quite old. Now, are there any others better approaches? (If you happen to know)
I know that its depend on data access pattern (i.e. cache miss). I still want to hear more opinion/argument about it, because I may need to rewrite a large part of my engine to make it support 30,000+ entity (personal greed).
Thank.



