Guys, I've spent a lot of time to load skeletal animation
but It is very difficult...
I refer to http://ogldev.atspace.co.uk/www/tutorial38/tutorial38.html
but I didn't get the results I wanted
Please Help Me
This is my codes
void LoadAnimation::BoneTransform(float time, vector<XMFLOAT4X4>& transforms)
{
XMMATRIX Identity = XMMatrixIdentity();
float TicksPerSecond = (float)(m_pScene->mAnimations[0]->mTicksPerSecond != 0 ?
m_pScene->mAnimations[0]->mTicksPerSecond : 25.0f);
float TimeInTicks = time*TicksPerSecond;
float AnimationTime = fmod(TimeInTicks, (float)m_pScene->mAnimations[0]->mDuration);
ReadNodeHeirarchy(AnimationTime, m_pScene->mRootNode, Identity);
transforms.resize(m_NumBones);
for (int i = 0; i < m_NumBones; ++i) {
XMStoreFloat4x4(&transforms[i], m_Bones[i].second.FinalTransformation);
}
}
void LoadAnimation::ReadNodeHeirarchy(float AnimationTime, const aiNode * pNode, const XMMATRIX& ParentTransform)
{
string NodeName(pNode->mName.data);
const aiAnimation* pAnim = m_pScene->mAnimations[0];
XMMATRIX NodeTransformation = XMMATRIX(&pNode->mTransformation.a1);
const aiNodeAnim* pNodeAnim = FindNodeAnim(pAnim, NodeName);
if (pNodeAnim) {
aiVector3D scaling;
CalcInterpolatedScaling(scaling, AnimationTime, pNodeAnim);
XMMATRIX ScalingM = XMMatrixScaling(scaling.x, scaling.y, scaling.z);
ScalingM = XMMatrixTranspose(ScalingM);
aiQuaternion q;
CalcInterpolatedRotation(q, AnimationTime, pNodeAnim);
XMMATRIX RotationM = XMMatrixRotationQuaternion(XMVectorSet(q.x, q.y, q.z, q.w));
RotationM = XMMatrixTranspose(RotationM);
aiVector3D t;
CalcInterpolatedPosition(t, AnimationTime, pNodeAnim);
XMMATRIX TranslationM = XMMatrixTranslation(t.x, t.y, t.z);
TranslationM = XMMatrixTranspose(TranslationM);
NodeTransformation = TranslationM * RotationM * ScalingM;
}
XMMATRIX GlobalTransformation = ParentTransform * NodeTransformation;
int tmp = 0;
for (auto& p : m_Bones) {
if (p.first == NodeName) {
p.second.FinalTransformation = XMMatrixTranspose(
m_GlobalInverse * GlobalTransformation * p.second.BoneOffset);
break;
}
tmp += 1;
}
for (UINT i = 0; i < pNode->mNumChildren; ++i) {
ReadNodeHeirarchy(AnimationTime, pNode->mChildren[i], GlobalTransformation);
}
}
CalcInterp~ function and Find~ function are like a tutorial
(http://ogldev.atspace.co.uk/www/tutorial38/tutorial38.html)
I think that I'm doing the multiplication wrong
but I don't know where it went wrong
If you want, i wall post other codes.
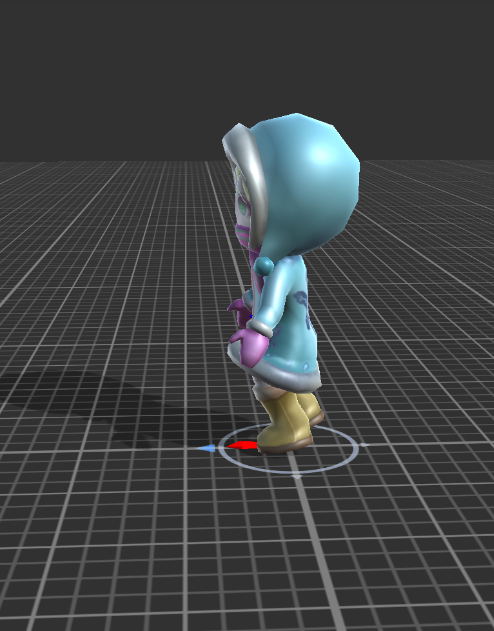
here is my result
(hands are stretched, legs are strange)

and it is ideal result