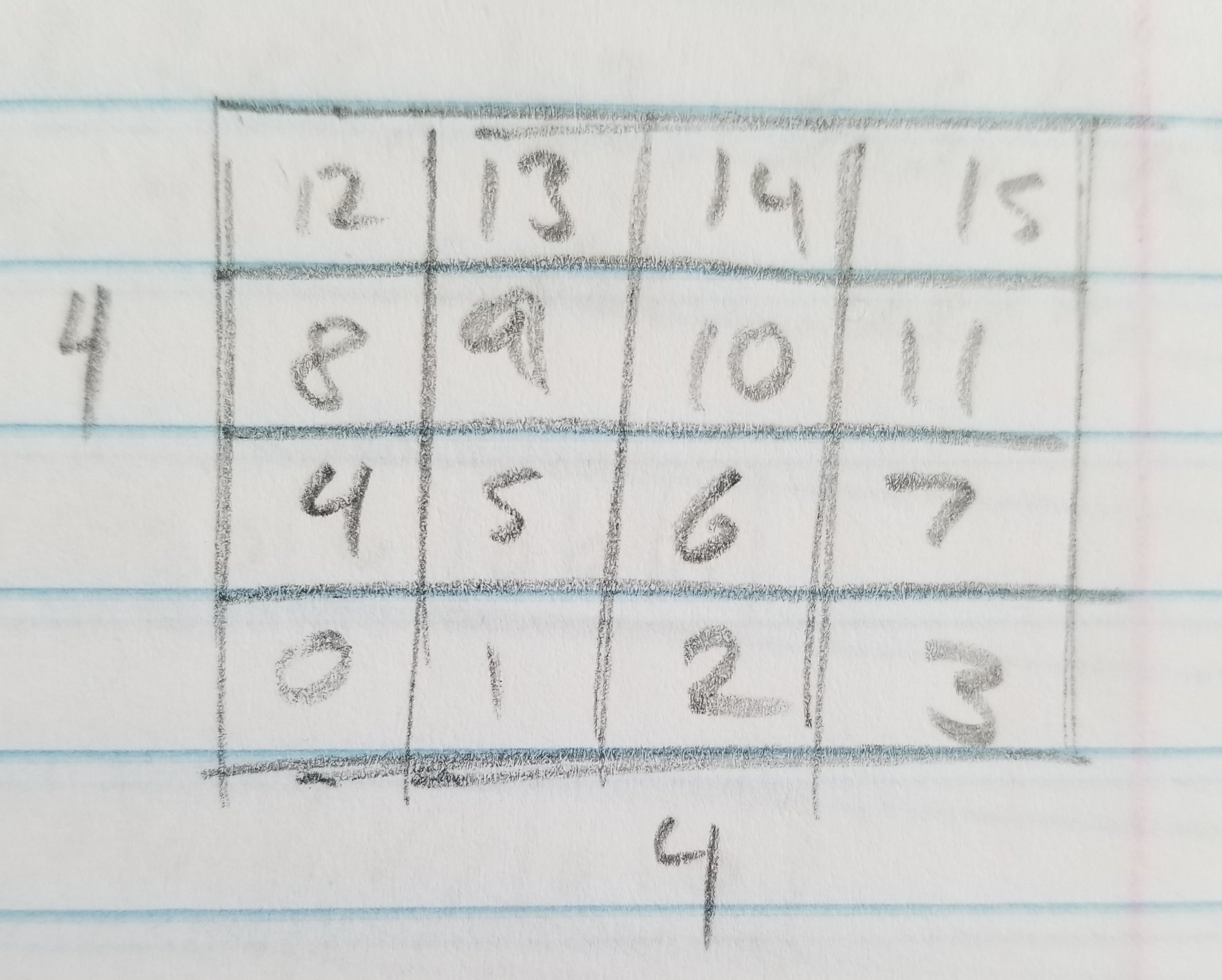
Hey guys, I'm writing a software renderer for fun and I decided to try and optimize the renderer by storing the frame buffer and depth buffer as rows of 2x2 blocks of pixels. I figured it would be easier to SIMDify and be more cache local. My main function for the software renderer is traversing boxes on the screen to either check for occlusion or to color in pixels. So if my pixel format is rows of pixels, then the main thing I perform is this:
void draw(u32* Pixels, int minx, int miny, int maxx, int maxy)
{
u32* PixelRow = Pixels + NumPixelsX*MinY + MinX;
for (u32 Y = miny; Y < maxy; ++Y)
{
u32* CurrPixel = PixelRow;
for (u32 X = minx; X < maxx; ++X)
{
*CurrPixel++ = some color/depth;
}
PixelRow += NumPixelsX;
}
}I converted this routine to SIMD and to process 2x2 pixels, but I found that by doing so, I added a big setup cost before the actual loop:
#define BLOCK_SIZE 2
#define NUM_BLOCK_X (ScreenX / BLOCK_SIZE)
global __m128i GlobalMinXMask[] =
{
_mm_setr_epi32(0xFFFFFFFF, 0xFFFFFFFF, 0xFFFFFFFF, 0xFFFFFFFF),
_mm_setr_epi32(0, 0xFFFFFFFF, 0, 0xFFFFFFFF),
};
global __m128i GlobalMaxXMask[] =
{
_mm_setr_epi32(0xFFFFFFFF, 0xFFFFFFFF, 0xFFFFFFFF, 0xFFFFFFFF),
_mm_setr_epi32(0xFFFFFFFF, 0, 0xFFFFFFFF, 0),
};
global __m128i GlobalMinYMask[] =
{
_mm_setr_epi32(0xFFFFFFFF, 0xFFFFFFFF, 0xFFFFFFFF, 0xFFFFFFFF),
_mm_setr_epi32(0, 0, 0xFFFFFFFF, 0xFFFFFFFF),
};
global __m128i GlobalMaxYMask[] =
{
_mm_setr_epi32(0xFFFFFFFF, 0xFFFFFFFF, 0xFFFFFFFF, 0xFFFFFFFF),
_mm_setr_epi32(0xFFFFFFFF, 0xFFFFFFFF, 0, 0),
};
inline void DrawNode(u32* Pixels, u32 MinX, u32 MaxX, u32 MinY, u32 MaxY)
{
// NOTE: All of this is the setup cost right here
u32 BlockMinX = MinX / BLOCK_SIZE;
u32 BlockMaxX = MaxX / BLOCK_SIZE;
u32 BlockMinY = MinY / BLOCK_SIZE;
u32 BlockMaxY = MaxY / BLOCK_SIZE;
u32 DiffMinX = MinX - BLOCK_SIZE*BlockMinX;
u32 DiffMaxX = MaxX - BLOCK_SIZE*BlockMaxX;
u32 DiffMinY = MinY - BLOCK_SIZE*BlockMinY;
u32 DiffMaxY = MaxY - BLOCK_SIZE*BlockMaxY;
if (DiffMaxX)
{
BlockMaxX += 1;
}
if (DiffMaxY)
{
BlockMaxY += 1;
}
f32* RowDepth = RenderState->DepthMap + Square(BLOCK_SIZE)*(BlockMinY*NUM_BLOCK_X + BlockMinX);
__m128 NodeDepthVec = _mm_set1_ps(Z);
for (u32 Y = BlockMinY; Y < BlockMaxY; ++Y)
{
f32* DepthBlock = RowDepth;
for (u32 X = BlockMinX; X < BlockMaxX; ++X)
{
__m128i Mask = _mm_set1_epi32(0xFFFFFFFF);
if (X == BlockMinX)
{
Mask = _mm_and_si128(Mask, GlobalMinXMask[DiffMinX]);
}
if (X == BlockMaxX - 1)
{
Mask = _mm_and_si128(Mask, GlobalMaxXMask[DiffMaxX]);
}
if (Y == BlockMinY)
{
Mask = _mm_and_si128(Mask, GlobalMinYMask[DiffMinY]);
}
if (Y == BlockMaxY - 1)
{
Mask = _mm_and_si128(Mask, GlobalMaxYMask[DiffMaxY]);
}
__m128 CurrDepthVec = _mm_maskload_ps(DepthBlock, Mask);
__m128 Compared = _mm_cmp_ps(CurrDepthVec, NodeDepthVec, _CMP_GT_OQ);
Mask = _mm_and_si128(Mask, _mm_castps_si128(Compared));
_mm_maskstore_ps(DepthBlock, Mask, NodeDepthVec);
DepthBlock += 4;
}
RowDepth += Square(BLOCK_SIZE)*NUM_BLOCK_X;
}
}(The min/max masks are if the min/max values fall inside a 2x2 block of pixels, we want to mask out writing/reading the pixels that aren't actually part of our range).
Calculating the block min/max as well as the diff min/max all seems to be a little much, I'm not sure if there is a much more efficient way to do that. I also wanted to take advantage of 8 wide SIMD using AVX so I figured I would have rows of 4x4 pixels, but where each block of 4x4 pixels itself stores 4 blocks of 2x2 pixels. Im worried that doing that will add a even larger setup cost to the loop which for my application would negate most of the benefits.
My bottom line is, I want to optimize as much as I can the process of filling a box of pixels on the screen with a color because my software renderer does it a lot every frame (4 million times currently), and I figured storing pixels in 2x2 blocks would make it faster, but I'm not sure if I'm missing some trick to more quickly calculate which pixels I have to iterate over.