2 hours ago, Fulcrum.013 said:
Ok. Looks like components will be allocated from pool by one at time, becouse binded to objects by ref. So why not to make a pools by segmented arrays that not need to be reallocated on enlarging and also can drop segments without move a content in case its segment complitelly free? Also it can have a queque of deleted slots to O(1) search a slot for reuse in fragmentated pool.
I think we're talking a different layer. This is like talking about std::vector that I hope can work on top of my memory allocation right now, asking how to use custom STL allocator using indirect memory access. Don't get me wrong though I like your idea, I am probably even just gonna use stack-based data structure for it, but that component thing I explained is just an example of how I will utilize the memory allocation under-the-hood for it, but not how these components will be handled/structured like this.
Quote
To reuse a slots from same pool or to srink a pool? First can be done without defragmentation, second have no any sence on realtime systems.
Shrink the pool. It does from what I tested. It's done gradually by a separate worker, defragmenting parts of the memory per loop within allocated budget that is acceptable by me so far. Unless your data is too large and your pool is also too large, which is not my case. They're just managing game object information so I don't think the memory usage (so far!) isn't really that big. Not more than 50 mb pool in total I think, could be way less depending on the environment (or the designer goes crazy). The pool can be even smaller if they're segmented per thread worker, still in theory though, cause I don't need it yet, but possible to make.
Quote
By best practicles of realtime software it have to avoid dynamic memory reallocations and have all required memory on hands anytime. If you have enought buffers/pools size allocated on start it no any needs to shrink it.
The whole memory for the game has been reserved first hand. But that also means I got to manually manage them virtually, and that involves all techniques including shrink, grow, best fit, close to fit, reallocating, list, whatever works to make sure I have enough space on these game objects that come (even worst, burst) and go pretty fast, CPU cache friendly, and better locality of reference. Please don't assume I'm using default malloc/free for every single small allocation for this.
Quote
Also in case it not enought space in any buffer system is already broken , becouse it mean that system can not process data at time and is not a realtime system anymore, regardless is it able or unable to enlarge buffers (for "soft" realtime it applicable only partially, so enlarging buffers by adding new segments to pool may help reanimate system on some cases). Also realtime systems have to avoid operations with unpredicable time like defragmentations, GC and so on to be a realtime.
Not in this case. Gameplay programmer needs rapid iterations of features over memory management. I give freedom of that but also flexibility if they wanna go deeper, whether if it's still inside the garbage-collected pool or outside. If you're talking about low level codes like rendering, that's a different stuff, and I'm not even talking about that, as if I'm using this GC for everything. I have mentioned it very clearly in my very first sentence, this is ONE of my memory allocator of many. It is the only one that is managed by the defragmenter. The rest returns normal pointers to objects in buffer.
Quote
It is same problem - object moved while have a refs/indexes that point to it old location that became invalid. It is only two ways to renew a pointers. First way is to build pointers map walking from root using a full RTTI data before defrgmentation just like Java or C# "stop-the -world" GC defragmentator do. It have no any sence especially for realtime system, becouse after it you may start to defrag again heap that has been used to build map.. Second way is to keep in objects addresses of all refs to it anytime (2-way pointers), and update it on reallocations of object. It very powerfull method that also required for many other purposes, like automatic nulling/removing from lists refs to object that destroyed/selfdestroyed while it have active refs, O(1) check is object allready exists in specific predefined role list and so on. But usually full implementation of 2-way is complete overkill, becouse for most classes list of refs and roles of its known and also number of refs can be limited by its known role refs.
Really it thing that usually better to do on start and do it universally, becouse it save many many screens of code, that use containers and especially 2-way ptrs into it.
I thought about that too already but I don't think renewing the pointers is a good idea. I'd rather keep track a good chunk of data that has a chance that they're deallocated in batch than updating the pointer table that may not be there anymore, for each pointer, which means allocation and deallocation gets more overhead to take care of the pointer table.
As for number two, yes exactly. As promising as it could be of two way pointers, it's basically the same as number one to me, but worse cause of lack of locality of reference I think (accessing random addresses to update addresses that are also somewhere random in the heap). And if there are more than one pointers to update, then it's more problem. It's not a option I guess.
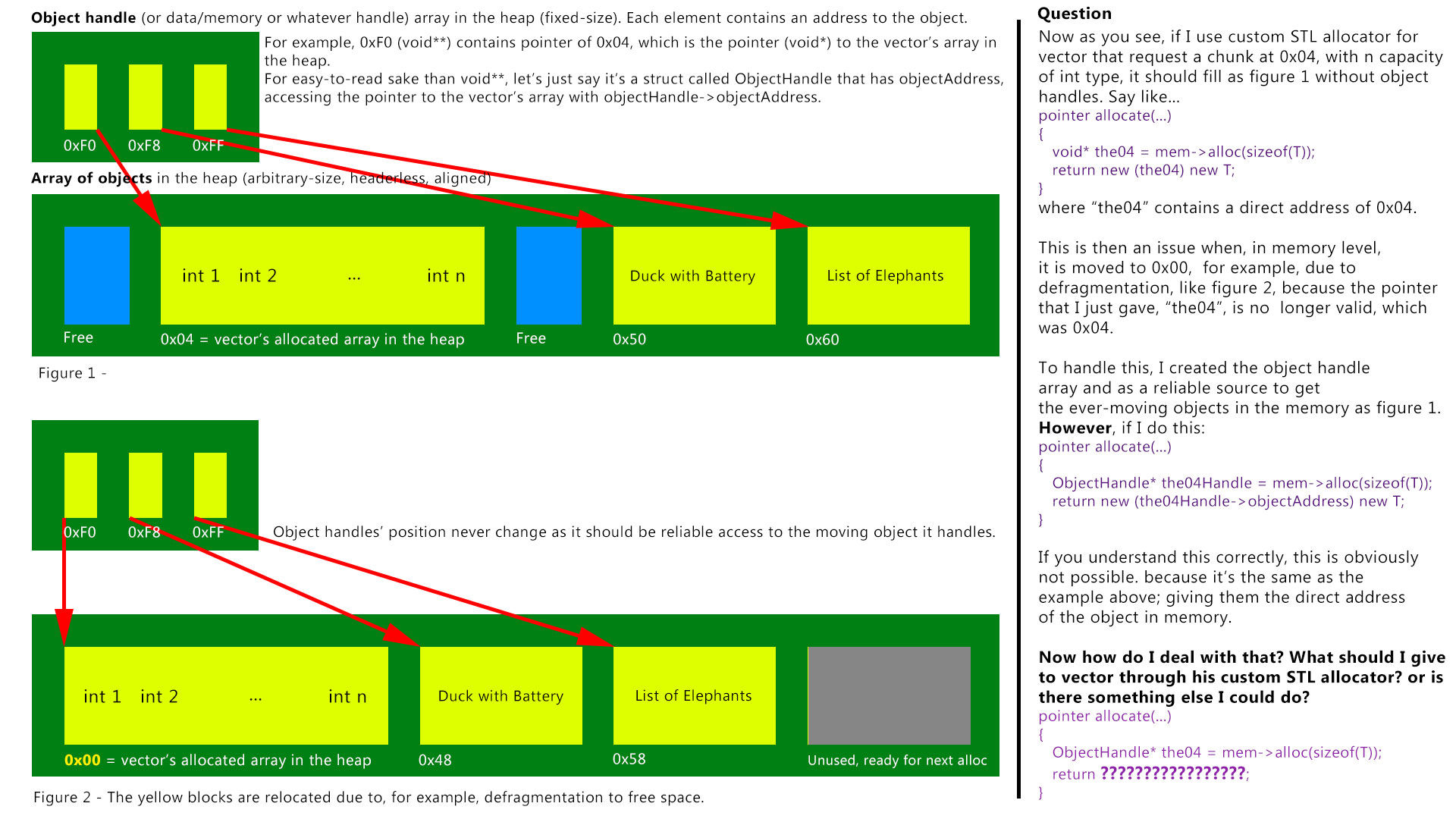
Anyway, I assume you understand better by now what I'm trying to do so.... to the actual question... I assume I can't provide custom STL allocator through indirect memory access, such as that pointer to the pointer of object in the buffer and is expected to reinvent the wheel in this one?