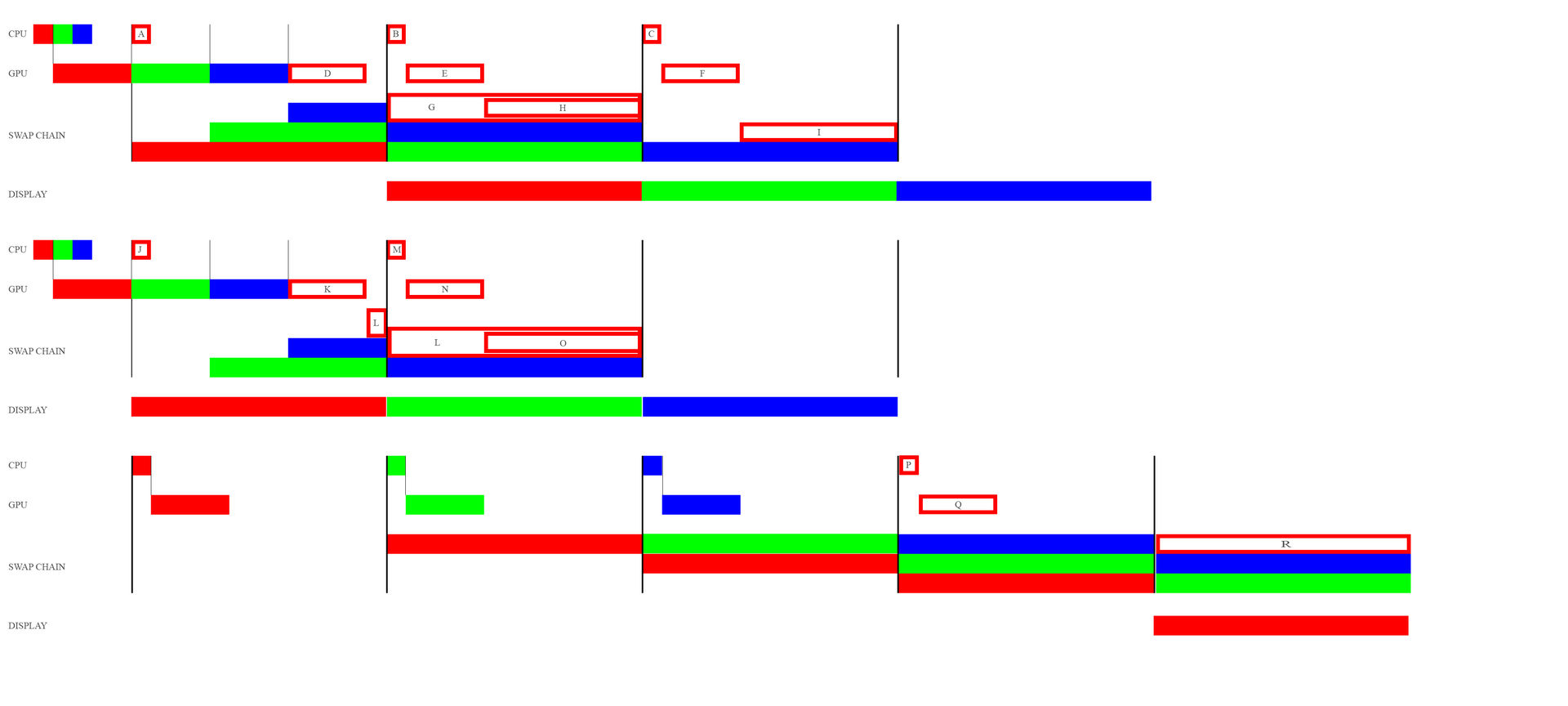
I have been trying to figure out how does fence and present synchronize the pipeline when using vsync.
https://www.gamedev.net/forums/topic/677527-dx12-fences-and-swap-chain-present/,
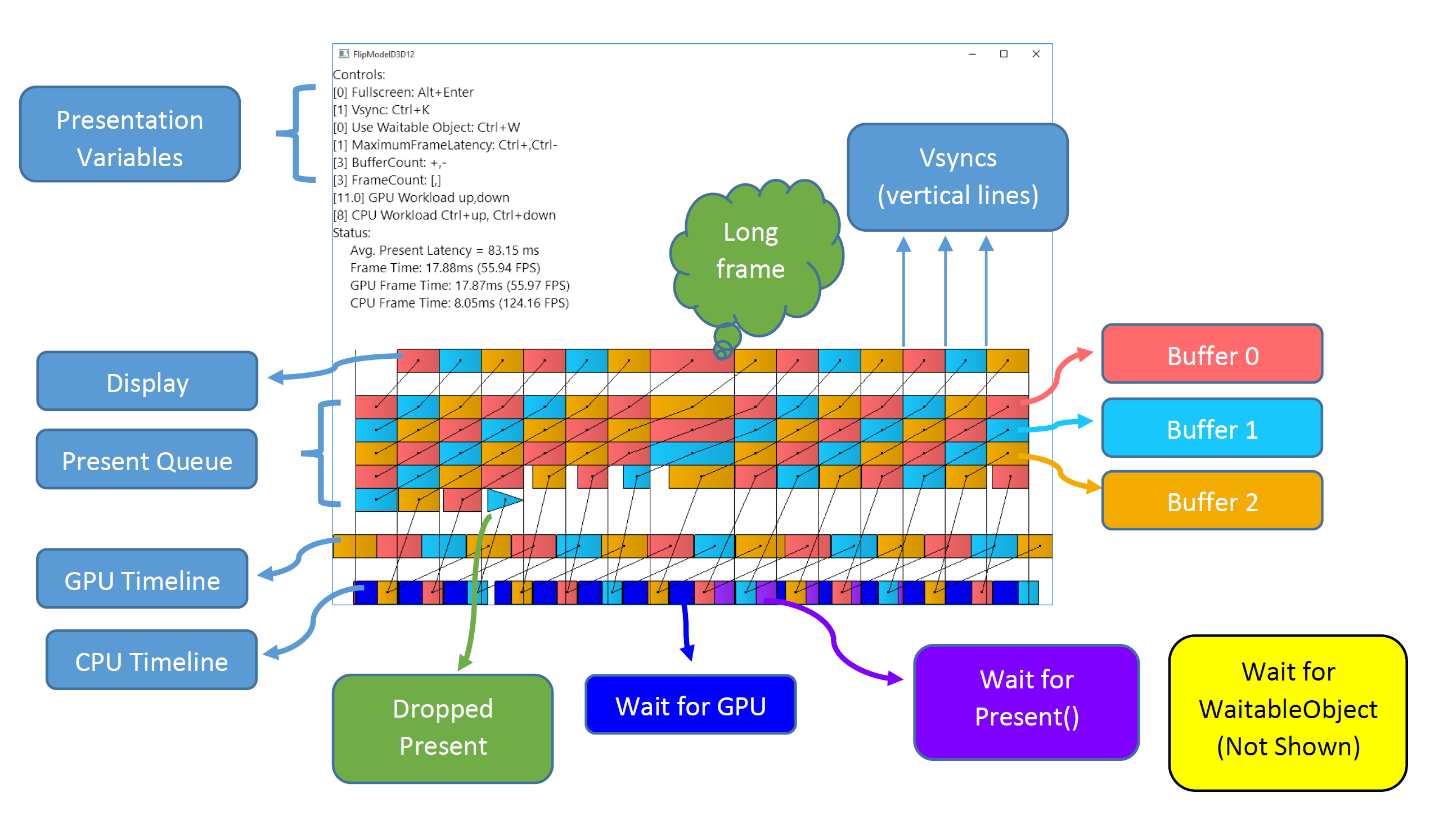
https://software.intel.com/en-us/articles/sample-application-for-direct3d-12-flip-model-swap-chains
and https://docs.microsoft.com/en-us/windows/desktop/api/dxgi/nf-dxgi-idxgiswapchain-present.
But I'm still a little confuesd. My major question is, assuming we are using triple buffer, will Present block cpu thread? If yes, when will it block cpu thread?
I made this picture, please tell me which combination is the correct situation for next frame? In my opinion it should be B,E,H. But if it is really B,E,H, it doesn't conform to what the link#4 suggest under the classic mode section. As a matter of fact, I don't even understand how could GPU thread be 2 vsync late than CPU thread in the first place in that situation. Also, if it is really B,E,H, it doesn't conform to what Nathan Reed suggested in link#1. It seems in his example, cpu thread is not throttled by Present or vsync at all. Cpu threads start to work right after gpu finish its work.