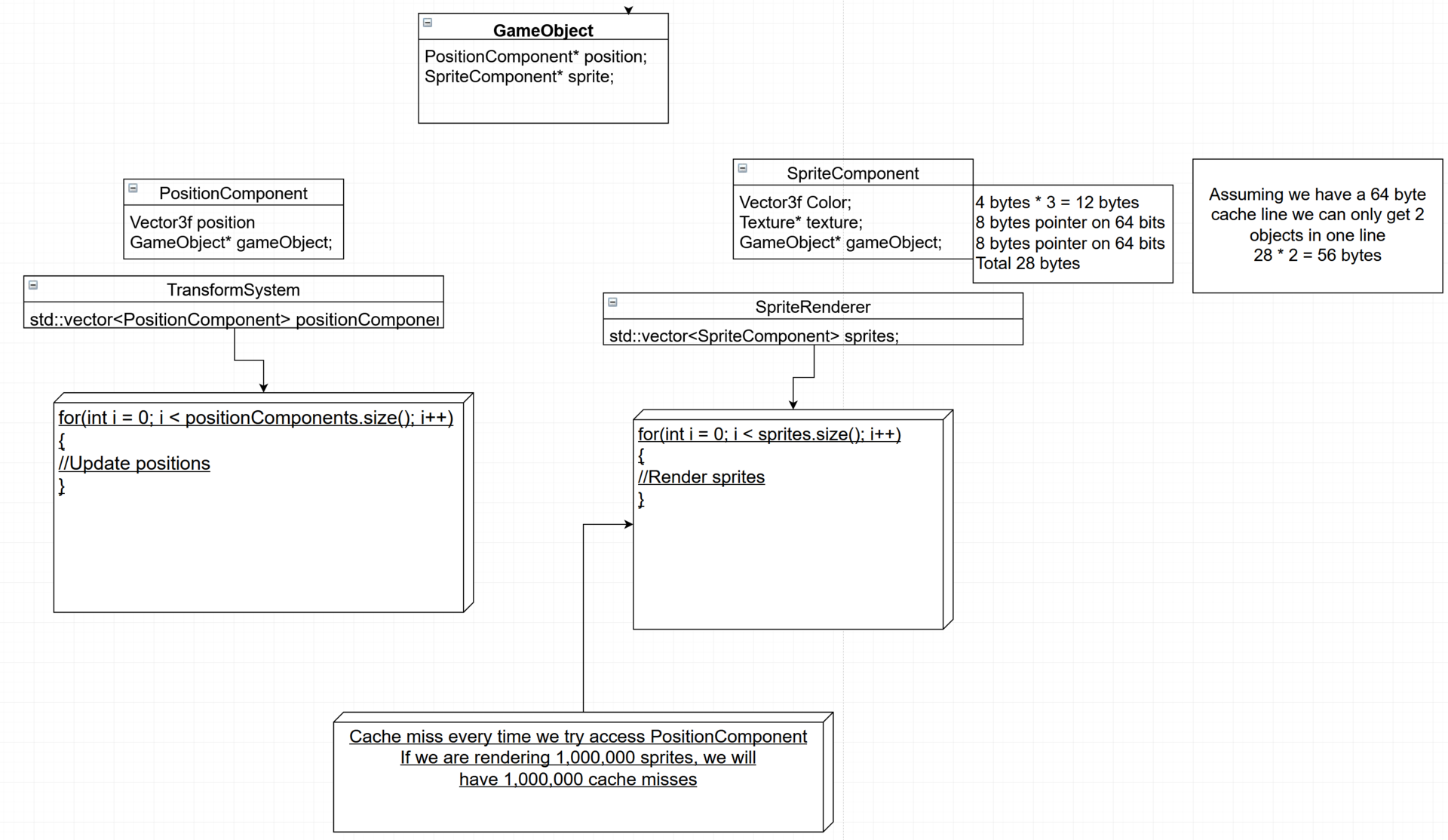
As wintertime points out, the GameObject is not needed, but I think that there is a missunderstanding involved here about what/why/where the issues are. Break it down conceptually to the most primitive level of what an Ecs represents as follows:
// Assume you have one entry in each of these items for each entity and they are both in order.
std::vector<Position> positions;
std::vector<Sprites> sprites;
for (size_t i=0; i<positions.size(); ++i)
{
auto& p = positions[i];
auto& s = sprites[i];
... do stuff ...
}
This is basically what you are trying to accomplish with the Ecs. Now, I think from reading your description you may be having a misconception that the above has a cache problem when in fact this is a near optimal access pattern. Cpu's are multi-associative when it comes to caching, meaning that they can track multiple streams of memory simultaneously. Or, in other words, once this loop has been primed there will be no cache misses caused by p & s being in separate areas of memory, the Cpu will just maintain two cache lines simultaneously. Additionally, the compilers may be smart enough to unroll the loop and do some optimizations based on this easily predicted memory access pattern, if not you can do it by hand of course. So, this is exactly what you are attempting to accomplish with the Ecs and it is a very good thing.
Now, the downside of Ecs is actually maintaining things such that the above is what you are actually accomplishing. This is where Ecs gets complicated and also where I believe a lot of confusion and dislike of the pattern comes from because so many implementations do it poorly. Just for example, take 4 entities with a p&s component, what you want in memory is the following:
e 0, 1, 2, 3
p 0, 1, 2, 3
s 0, 1, 2, 3
Assume that you remove the 's' component from entity 1 and you end up with:
e 0, 1, 2, 3
p 0, 1, 2, 3
s 0, 3, 2
You have just broken the iteration pattern if you are using sparse arrays per component since now when you iterate 0..3 based on the entity index you are no longer linearly indexing into the s array. Overtime, this gets so disorganized that you are not getting any real benefits over a normal OO pattern (actually it generally gets slower) and generally speaking Ecs becomes a waste unless the only thing you care about is minimizing memory overhead.
To solve such things there are several approaches, one is to do lazy sorts where over time you reorganize the 's' array to be linear. This is relatively simple to implement and honestly not the most horrible thing in the world but if you have a lot of add/remove going on, you may never get the sorting to stabilize. The second and more common high performance solution is archetypes/groups. This can be rather complicated and has it's own set of performance gaffs though. Generally speaking, a really simple outline of archetypes is that you end up with the following after removing the component:
Group p+s
e 0, 3, 2
p 0, 3, 2
s 0, 3, 2
Group p
e 1
p 1
How this works is that you don't use the 'e' as an index, that's just a reverse map to the original entity id and other than internal management it is pretty much ignored. More importantly you have these two different groups (separate arrays which means we had to copy e+p into the new 'p' group) now rather than disjoint arrays. So, if you need to iterate p+s, you only iterate that group and ignore the 'p' group. If you need to iterate all things with 'p', you end up performing the iteration twice, once over p and once over p+s. This can be difficult to maintain and complicates things but once again you are back to the original performance intentions of Ecs in terms of maintaining linear data access at all times.
Anyway, hope this is helpful, Ecs has a great number of advantages and an equally great number of disadvantages and misunderstandings.