3 minutes ago, MasterReDWinD said:
Were you generating the mesh from scratch or converting one that you already had? You mentioned full mesh editing. That is something I am also targetting.
I did it for loading indexed meshes to get started. For this reason i made the simple solution using std::map.
I use the mesh editing because i work on quadrangulation, and i made edit operations like create polys, edge collapse, edge rotation etc. Likely the same stuff you would need for dynamic LOD. While working on this i realized the map is not necessary.
12 minutes ago, MasterReDWinD said:
It probably makes much more sense to get the mesh out of Surface Nets in half-edge format to begin with
Maybe yes - makes sense, but not sure. Converting indexed mesh to half-edge could be just as good. (The example below is more the kind of half edge mesh from indexed)
15 minutes ago, MasterReDWinD said:
How did you find the performance in your case?
I do not target realtime, but here an example (of how slow it is ") ):
):
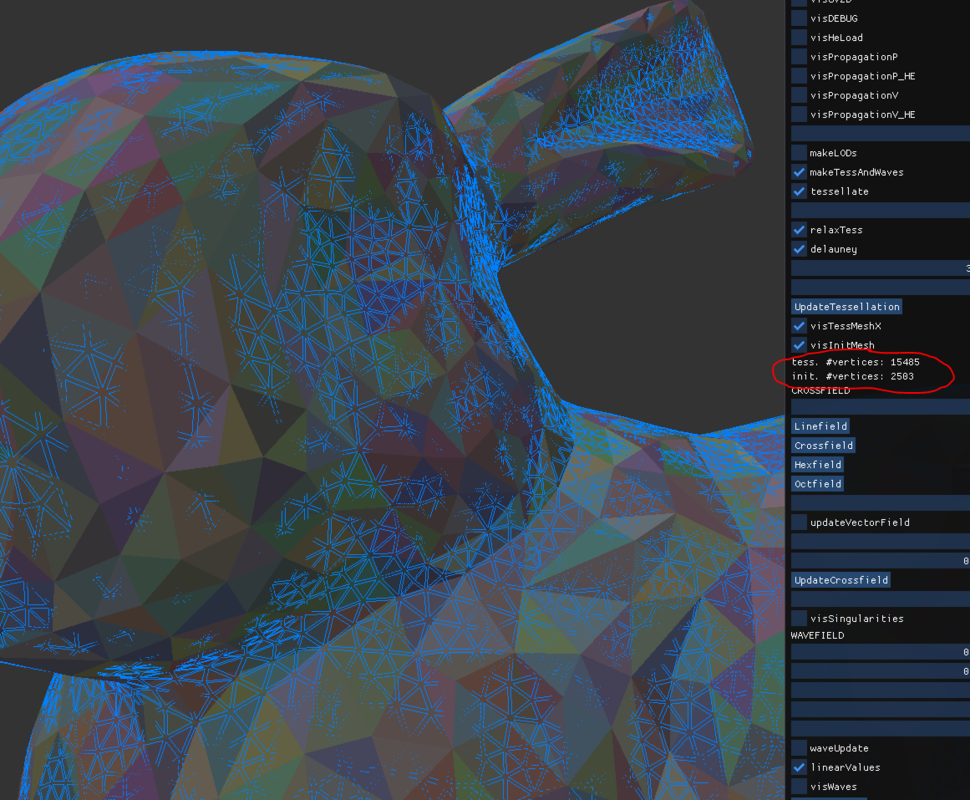
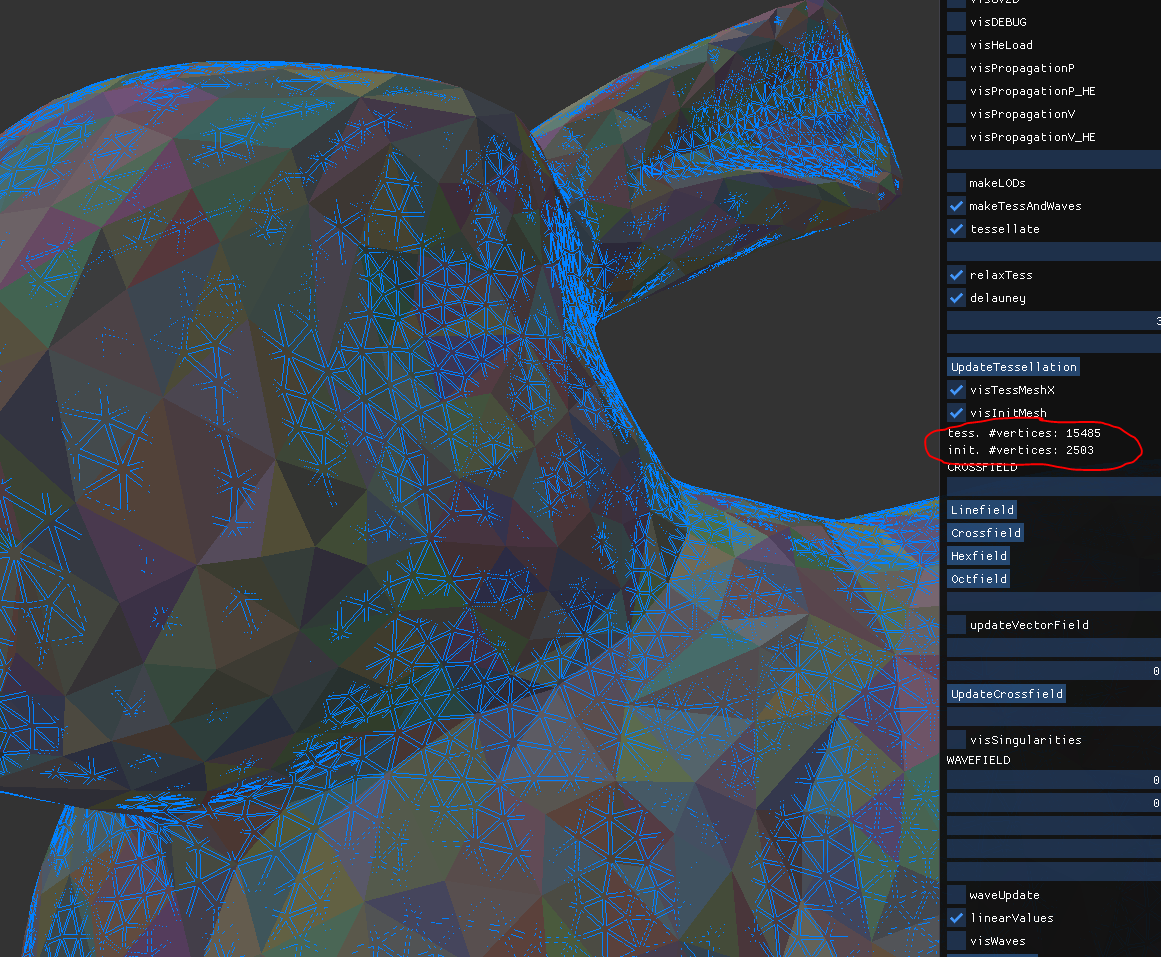
So that's a tessellated bunny model, with editing ops used for tessellation.
Input mesh (solid random color) has 2500 vertices, and the tessellation (blue wire) has 15500. Takes about 7 seconds on single core.
(looks like delauney, but i use a trick to align hex grids to triangles so i do not need expensive delauney triangulation algorithm. It's just connecting grid points to triangles, followed by edge flips and smoothing to improve the result - very most of those 7 seconds are used for mesh creation and editing.)
I have no idea how fast such things can be for realtime use. I do only care about time complexity and try to reserve memory whenever possible.
Multithreading, cache efficiency, avoiding dynamic allocation... that's definitively a lot of work to make such stuff fast.
( @Gnollrunner should be able to give a much better answer)
Anyways, i would still think about alternatives first. For example, if you have a volume, would it work to downscale the volume, make surface net on GPU and transfer this back to CPU?
Mesh simplification (which i assume you want to do on CPU from high res surface net) sounds like you could loose a lot from the advantage to generate your stuff on GPU so far.
I have a mesh simplification stage as well in my project, which uses edge collapses and a priority queue - pretty standart, and not so suited for realtime. Here some work of a guy who tired to avoid the need for a queue, but not aiming realtime either: http://voxels.blogspot.com/2014/05/quadric-mesh-simplification-with-source.html
For realtime usually people try to precalculate the simplification process, like progressive meshes do.
To me it seems much less work to downscale the volume and then use some isosurface extraction.