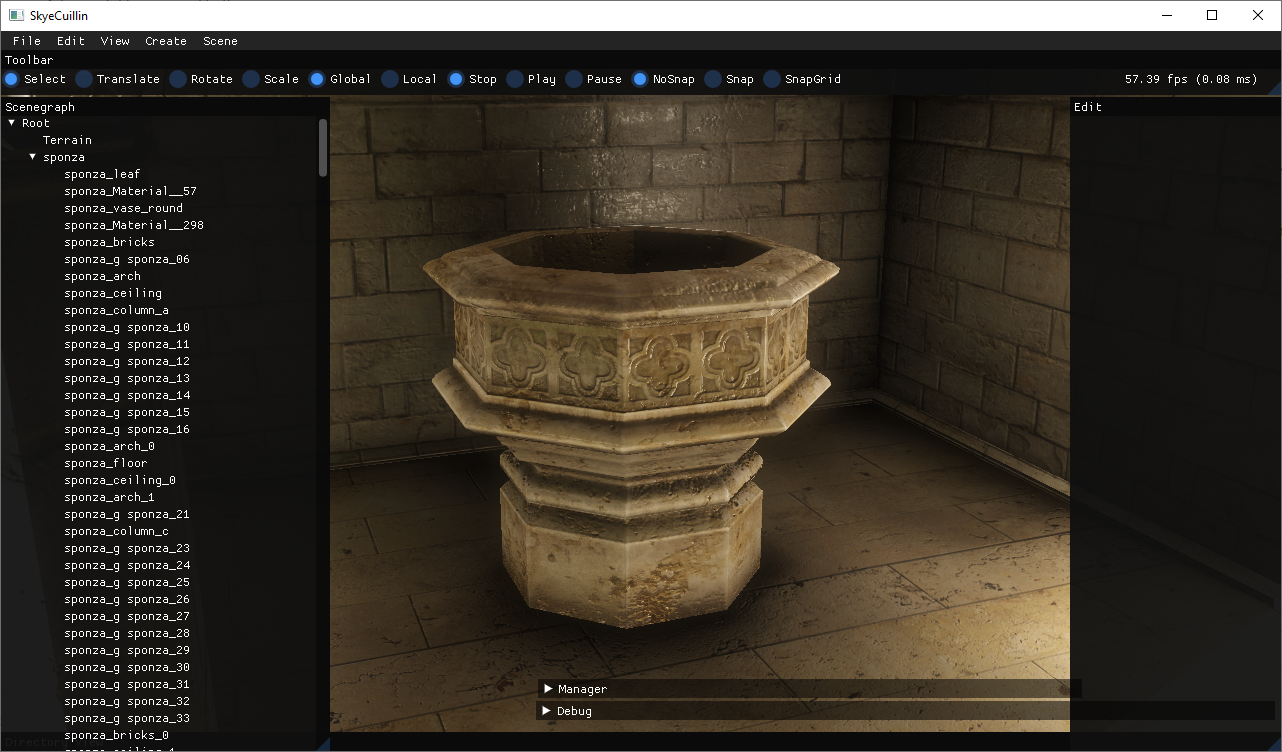
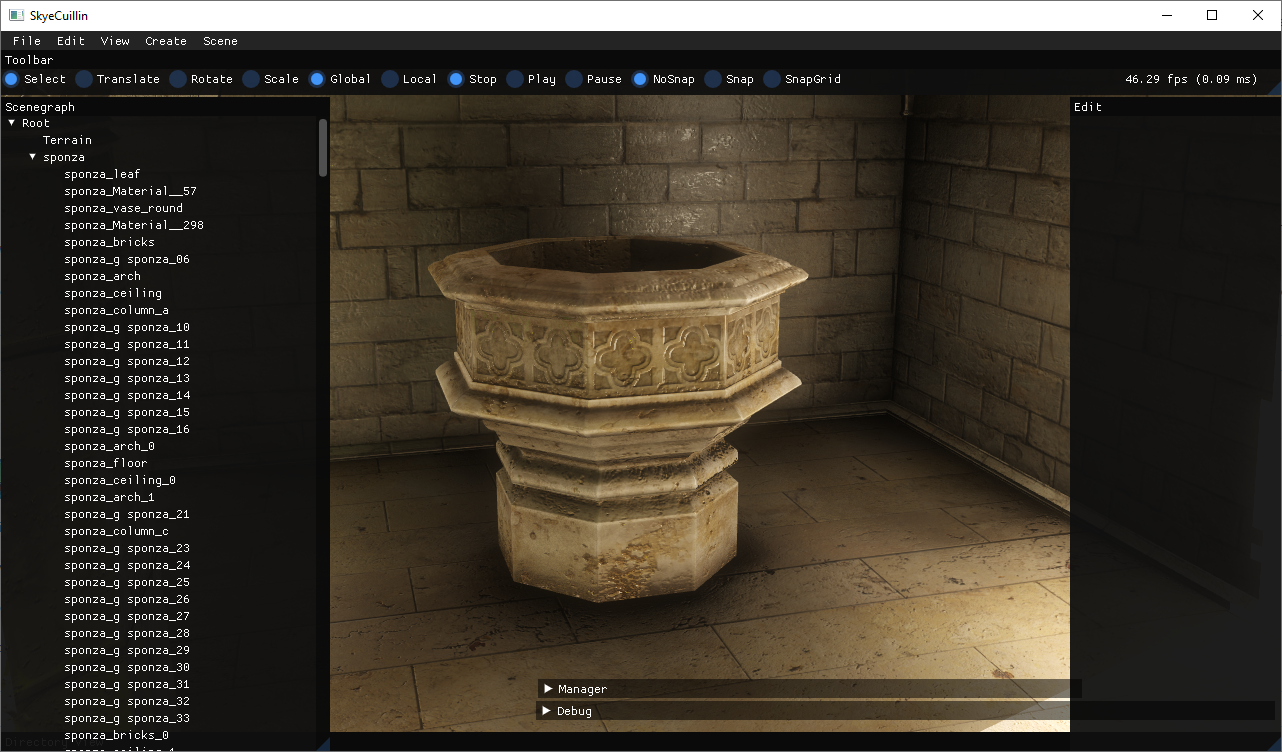
So, I've deep dived into my MSAA items, and I'm still thinking about how to properly resolve it?
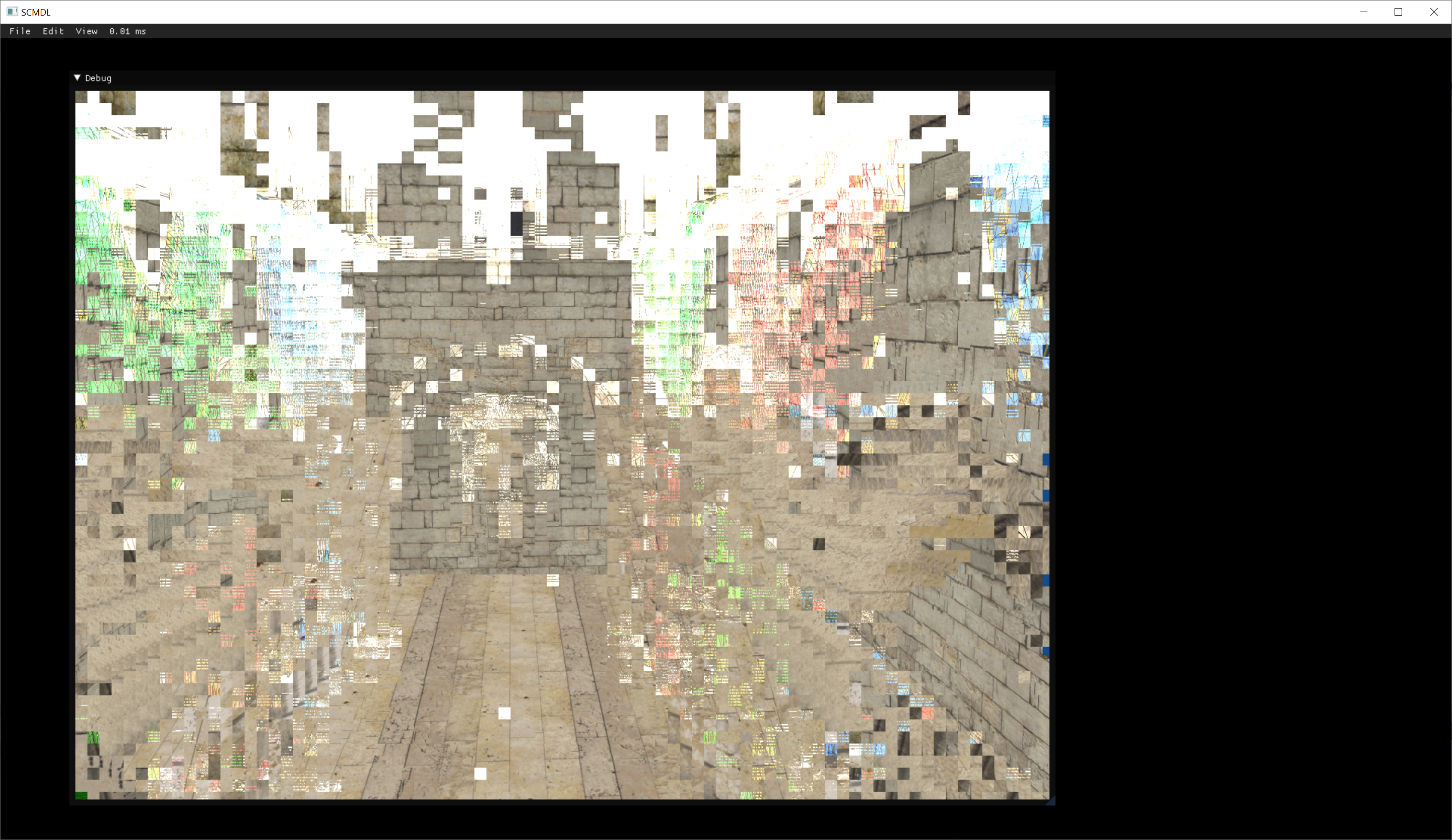
Previously (and for years) I've just looped over N samples and resolved, but naturally this doesn't need to be done everywhere, because it's just going to waste computation power on samples which don't need to be resolved. Here is a mask of which samples actually have different values (and which have the same):
While it is still quite some, in case of Sponza (Crytek version) we're talking about fraction of pixels requiring resolving. Now - as I'm correctly resolving after all processing in post-tonemap phase, doing all the phases over N samples is going to be computationally intensive (this may count double for calculating GI per-sample). Now - the user can define the number of samples (1, 2, 4, 8) for MSAA.
So, what are my options (throw in more if you can think off any):
- Do processing per-sample everywhere (the most simple, but wastes a LOT of resources)
- Store this mask - and then:
- For pixels in mask, resolve over ALL samples
- For pixels outside of mask, resolve only 1st sample
- Store this mask - and then:
- When processing per-tile (in tile-based approach - but what would be good tile size for this, 32x32 might be too big, 16x16 might be still too big)
- If there is any pixel with mask within tile, resolve ALL samples
- If there is no pixel with mask within tile, resolve only 1st sample
- When processing per-tile (in tile-based approach - but what would be good tile size for this, 32x32 might be too big, 16x16 might be still too big)
- Variant of 3., but apply 2. in case there is any pixel with mask within tile
- A variant of 2, but execute mask/non-mask pixels separately as 2 separate dispatches? Would require some additional data though (some packing/unpacking of the image) … that could be quite a nightmare to manage
The full pipeline is quite heavy on pixel-level processing (can and will cast cones or rays per-sample/per-pixel).
Now, the problem with 3 is, that some tiles are going to process N times more sample to process. Yet it could actually end up being better than in 2. As in 2, the whole warp (threadgroup) executing the current batch of pixels will wait for the slowest one. Now, this is just a speculation from ray tracers I've worked with in the past - but - could persistent-thread approach help here? That might be a bit too overkill though.