Hmm I do remember having some issues that no pixel shader was being executed....can't remember exactly what it was though...
Have you made sure that your InputLayout is correctly set ?
Should look something like this:
D3D11_INPUT_ELEMENT_DESC lo[] =
{
{"POSITION", 0, DXGI_FORMAT_R32G32B32_FLOAT, 0, 0, D3D11_INPUT_PER_VERTEX_DATA, 0 },
{"TEXCOORD", 0, DXGI_FORMAT_R32G32_FLOAT, 1, D3D11_APPEND_ALIGNED_ELEMENT, D3D11_INPUT_PER_VERTEX_DATA, 0},
{"NORMAL", 0, DXGI_FORMAT_R32G32B32_FLOAT, 2, D3D11_APPEND_ALIGNED_ELEMENT, D3D11_INPUT_PER_VERTEX_DATA, 0},
{"TANGENT", 0, DXGI_FORMAT_R32G32B32_FLOAT, 3, D3D11_APPEND_ALIGNED_ELEMENT, D3D11_INPUT_PER_VERTEX_DATA, 0},
};
fourth parameter is important here as this is the vertex buffer slot...
Also try to make sure the float4s are combined in the correct order.
I've had a lot of problems with this. In the end I had to transpose the matrix first and then pass them to the cbuffer because otherwise you'd loose the 4th row because
if you pass your 3 rows something like:
cbufferData.data = worldMatrix.r;
you're passing only 3 vectors of this matrix and you will loose important data if you pass the rows instead of the columns.
That's why I changed it over to columns and it worked:
float4x4 GetInstanceTransform(uint instID, uint offset)
{
uint BufferOffset = instID * elementsPerInstance + startIndex + offset;
float4 c0 = InstanceDataBuffer.Load(BufferOffset + 0);
float4 c1 = InstanceDataBuffer.Load(BufferOffset + 1);
float4 c2 = InstanceDataBuffer.Load(BufferOffset + 2);
float4 c3 = float4(0.0f, 0.0f, 0.0f, 1.0f);
float4x4 _World = { c0.x, c1.x, c2.x, c3.x,
c0.y, c1.y, c2.y, c3.y,
c0.z, c1.z, c2.z, c3.z,
c0.w, c1.w, c2.w, c3.w };
return _World;
}
I don't see a way around that...but maybe someone does ?


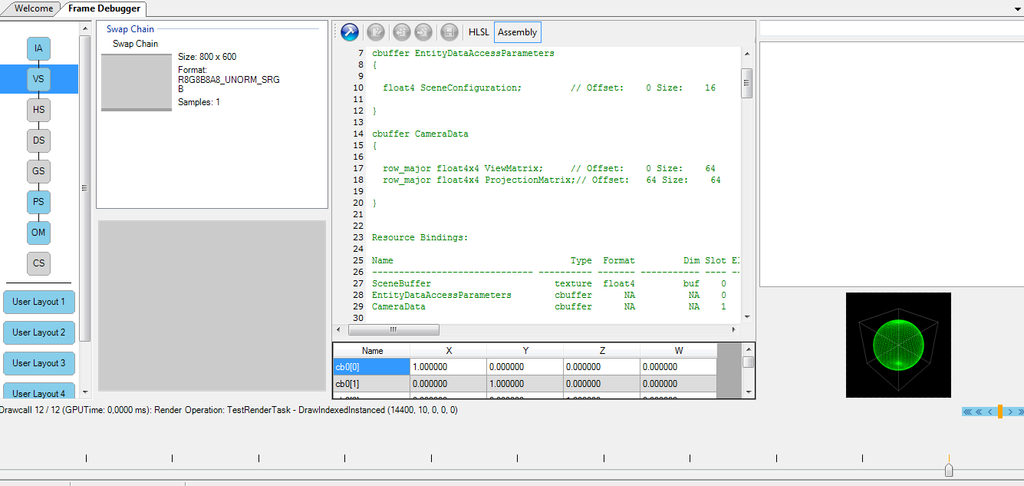 However nothing gets rasterized.It can't be the view matrix, since it works on normal rendering, so it has to be something to do with the large buffer object.Did you ever experience such an issue?
However nothing gets rasterized.It can't be the view matrix, since it works on normal rendering, so it has to be something to do with the large buffer object.Did you ever experience such an issue?