Fourth article in this complicated, code-deprived, dry-as-Metamucil series, and you're still reading? Drop me an email if you are, so that I know I'm writing these for a reason!
Anyway, this month's installment focuses on the basics of two-agent search in strategy games: why it is useful, how to do it, and what it implies for the computer's style of play. The techniques I will discuss apply equally well to most two-player games, but by themselves, they are not quite sufficient to play good chess; next month, I will describe advanced techniques which significantly increase playing strength and search efficiency, usually at the same time.
Why Search?
Well, basically, because we are not smart enough to do without it.
A really bright program might be able to look at a board position and determine who is ahead, by how much, and what sort of plan should be implemented to drive the advantage to fruition. Unfortunately, there are so many patterns to discern, so many rules and so many exceptions, that even the cleverest programs just aren't very good at this sort of thing. What they
are good at, however, is computing fast. Therefore, instead of trying to figure out good moves just by looking at a board, chess programs use their brute force to do it: look at every move, then at every possible countermove by the opponent, etc., until the processor melts down.
Deep searches are an easy way to "teach" the machine about relatively complicated tactics. For example, consider the knight fork, a move which places a knight on a square from which it can attack two different pieces (say, a rook and the queen). Finding a way to represent this type of position logically would require some effort, more so if we also had to determine whether the knight was itself protected from capture. However, a plain dumb 3-ply search will "learn" the value of a fork on its own: it will eventually try to move the knight to the forking square, will test all replies to this attack, and then capture one of the undefended pieces, changing the board's material balance. And since a full-width search looks at everything, it will never miss an opportunity: if there is a 5-move combination, however obscure, that leads to checkmate or to a queen capture, the machine
will see it if its search is deep enough. Therefore, the deeper the search, the more complicated the "plans" which the machine can stumble upon.
Grandpa MiniMax
The basic idea underlying all two-agent search algorithms is Minimax. It dates back from the Dark Ages; I believe Von Neumann himself first described it over 60 years ago.
Minimax can be defined as follows:
- Assume that there is a way to evaluate a board position so that we know whether Player 1 (whom we will call Max) is going to win, whether his opponent (Min) will, or whether the position will lead to a draw. This evaluation takes the form of a number: a positive number indicates that Max is leading, a negative number, that Min is ahead, and a zero, that nobody has acquired an advantage.
- Max's job is to make moves which will increase the board's evaluation (i.e., he will try to maximize the evaluation).
- Min's job is to make moves which decrease the board's evaluation (i.e., he will try to minimize it).
- Assume that both players play flawlessly, i.e., that they never make any mistakes and always make the moves that improve their respective positions the most.
How does this work? Well, suppose that there is a simple game which consists of exactly one move for each player, and that each has only two possible choices to make in a given situation. The evaluation function is only run on the final board positions, which result from a combination of moves by Min and Max.
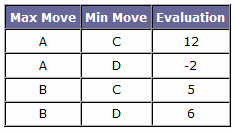
Max assumes that Min will always play perfectly. Therefore, he knows that, if he makes move A, his opponent will reply with D, resulting in a final evaluation of -2 (i.e., a win for Min). However, if Max plays B, he is sure to win, because Min's best move still results in a positive final value of 5. So, by the Minimax algorithm, Max will always choose to play B, even though he would score a bigger victory if he played A and Min made a mistake!
The trouble with Minimax, which may not be immediately obvious from such a small example, is that there is an exponential number of possible paths which must be examined. This means that effort grows dramatically with:
- The number of possible moves by each player, called the branching factor and noted B.
- The depth of the look-ahead, noted d, and usually described as "N-ply", where N is an integer number and "ply" means one move by one player. For example, the mini-game described above is searched to a depth of 2-ply, one move per player.
In Chess, for example, a typical branching factor in the middle game would be about 35 moves; in Othello, around 8. Since Minimax' complexity is O( B^n ), an 8-ply search of a chess position would need to explore about 1.5 million possible paths! That is a LOT of work. Adding a ninth ply would make the tree balloon to about 50 million nodes, and a tenth, to an impossible 1.8 billion!
Luckily, there are ways to cut the effort by a wide margin without sacrificing accuracy.
Alphabeta: Making Minimax Feasible (a little)
Suppose that you have already searched Max' move B in the mini-game above. Therefore, you know that, at best, Max' score for the entire game will be 5.
Now, suppose that you begin searching move A, and that you start with the path A-D. This path results in a score of -2. For Max, this is terrible: if he plays A, he is sure to finish with, at best, -2, because Min plays perfectly; if A-C results in a score higher than A-D's, Min will play A-D, and if A-C should be even worse (say, -20), Min would take that path instead. Therefore,
there is no need to look at A-C, or at any other path resulting from move A: Max must play B, because the search has already proven that A will end up being a worse choice no matter what happens.
This is the basic idea being the alphabeta algorithm: once you have a good move, you can quickly eliminate alternatives that lead to disaster. And there are
a lot of those! When combined with the transposition table we discussed earlier in the series, and which saves us from examining positions twice if they can be reached by different combinations of moves, alphabeta turns on the Warp drive: in the best case, it will only need to examine roughly twice the square root of the number of nodes searched by pure Minimax, which is about 2,500 instead of 1.5 million in the example above.
Ordering Moves to Optimize Alphabeta
But how can we achieve this best case scenario? Do we even need to?
Not really. It turns out that Alphabeta is always very efficient at pruning the search tree, as long as it can quickly find a pretty good move to compare others to. This means that it is important to search a good move first; the best case happens when we always look at the best possible moves before any others. In the worst possible case, however, the moves are searched in increasing order of value, so that each one is always better than anything examined before; in this situation, alphabeta can't prune
anything and the search degenerates into pure, wasteful Minimax.
Ordering the moves before search is therefore very important. Picking moves at random just won't do; we need a "smarter" way to do the job. Unfortunately, if there was an easy way to know what the best move would turn out to be, there would be no need to search in the first place! So we have to make do with a "best guess".
Several techniques have been developed to order the possible moves in as close to an optimal sequence as possible:
- Apply the evaluation function to the positions resulting from the moves, and sort them. Intuitively, this makes sense, and the better the evaluation function, the more effective this method should be. Unfortunately, it doesn't work well at all for chess, because as we will see next month, many positions just can't be evaluated accurately!
- Try to find a move which results in a position already stored in the transposition table; if its value is good enough to cause a cutoff, no search effort needs to be expended.
- Try certain types of moves first. For example, having your queen captured is rarely a smart idea, so checking for captures first may reveal "bonehead" moves rapidly.
- Extend this idea to any move which has recently caused a cutoff at the same level in the search tree. This "killer heuristic" is based on the fact that many moves are inconsequential: if your queen is en prise, it doesn't matter whether you advance your pawn at H2 by one or two squares; the opponent will still take the queen. Therefore, if the move "bishop takes queen" has caused a cutoff during the examination of move H2-H3, it might also cause one during the examination of H2-H4, and should be tried first.
- Extend the killer heuristic into a history table. If, during the course of the game's recent development, moving a piece from G2 to E4 has proven effective, then it is likely that doing so now would still be useful (even if the old piece was a bishop and has been replaced by a queen), because conditions elsewhere on the board probably haven't changed that much. The history heuristic is laughably simple to implement, needing only a pair of 64x64 arrays of integer counters, and yields very interesting results.
Having said all that about "reasonable ideas", it turns out that the most effective method is one which goes against every single bit of human intuition: iterative deepening.
Iterative Deepening AlphaBeta
If you are searching a position to depth 6, the ideal move ordering would be the one yielded by a prior search of the same position to the same depth. Since that is obviously impossible, how about using the results of a shallower search, say of depth 5?
This is the idea behind iterative deepening: begin by searching all moves arising from the position to depth 2, use the scores to reorder the moves, search again to depth 3, reorder, etc., until you have reached the appropriate depth.
This technique flies in the face of common sense: a tremendous amount of effort is duplicated, possibly 8-10 times or more. Or is it?
Consider the size of a search tree of depth d with branching factor B. The tree has B nodes at depth 1, B*B at depth 2, B*B*B at depth 3, etc. Therefore, searching to depth (d-1) yields a tree B times smaller than searching to depth d! If B is large (and remember that it is about 35 during the middle game in chess), the overwhelming majority of the effort expended during search is devoted to the very last ply. Duplicating a search to depth (d-1) is a trifling matter: in fact, even if it yielded no advantages whatsoever, iterative deepening would only cost less than 4% extra effort on a typical chess position!
However, the advantages are there, and they are enormous: using the results of a shallower search to order the moves prior to a deeper one produces a spectacular increase in the cutoff rate. Therefore, IDAB actually examines
far fewer nodes, on average, than a straight AB search to the same depth using any other technique for move ordering! When a transposition table enters the equation, the gain is even more impressive: the extra work performed to duplicate the shallow parts of the search drops to nothing because the results are already stored in the table and need not be computed again.
Computer Playing Style
Iterative deepening alphabeta combined with a transposition table (and a history table to kickstart the effort) allows the computer to search every position relatively deeply and to play a reasonable game of chess. That being said, its Minimax ancestor imposes a very definite playing style on the computer, one which is not exactly the most spectacular in the world.
For example, suppose that the machine searches a position to depth 8. While looking at a certain move, it sees that every possible response by the opponent would let it win the game in dazzling manner... Except for a single opaque, difficult, obfuscated and almost maddeningly counter-intuitive sequence, which (if followed to perfection) would allow the opponent to salvage a small chance of eventually winning the game. Against a human player (even a Grandmaster), such a trap might turn the game into one for the history books.
However, if the machine then finds a boring move which always forces a draw, it will immediately discard the trap, because it assumes that the opponent would find the perfect counter, no matter how improbable that is, and that the draw is the best it can hope for!
As a result, you might say that machines play an overly cautious game, as if every opponent was a potential world champion. Combined with the fact that computers often can't search deep enough to detect the traps which human players devise against them, this allows very skilled humans to "waste time" and confuse the machine into making a blunder which they can exploit. (Human players also study their opponent's styles for weaknesses; if Kasparov had been given access to, say, a hundred games played by Deep Blue before their match, he might have been able to find the flaws in its game and beat it. But we'll never know for sure.)
Next Month
In
Part V, we will discuss the limitations of straight, fixed-depth alphabeta search, and how to improve playing strength using techniques like the null-move heuristic, quiescence search, aspiration search and MTD(f), and the "singular extensions" which made Deep Blue famous. Hold on, we're almost done!
Fran?ois Dominic Laram?e, August 2000




Watch and follow along as the process of writing a chess engine is demonstrated and explained.
There are currently two tutorial series:
Write a simple Java chess engine with GUI in under 1,000 lines of code
OR
Write an advanced bitboard-based Java chess engine using modern techniques.
Subscribe to get email notifications on upcoming chess engine tutorial videos. (A new video is posted every Monday)