🎉 Celebrating 25 Years of GameDev.net! 🎉
Not many can claim 25 years on the Internet! Join us in celebrating this milestone. Learn more about our history, and thank you for being a part of our community!

January 09, 2020

A couple of months ago, out of boredom, I implemented the old plasma fractals algorithm that is emblematic of the late 1980s/early 1990s demoscene, “rectangle subdivision fractals” or whatever you want to call it. It’s an old hack. I wrote some code that would generate animated …
July 27, 2017

Recently I looked through a bunch of triangular cellular automata in which each (1) uses two states, (2) uses the simple alive cell count type of rule, and (3) uses the neighborhood around a cell c that is all the triangles that share a vertex with c; that is, the 12 shaded triangles below are t…
October 14, 2015
[color=rgb(40,40,40)][font='Times New Roman']A couple of weeks ago I got interested in this project but wanted full control of the code, wanted to know exactly what it is doing, wanted a bunch of features like the ability to import and export CA rules, and wanted to have the process not be seeded b…
May 14, 2015

[color=#282828][font='Times New Roman']Below is gameplay video of a prototype of the puzzle game "Draak" that I am working on. Draak will be an iPad-only iOS game; the prototype below is written to Windows in C# on top of MonoGame.[/font][/color]
[media] [/media]
[media] [/media]
January 29, 2015
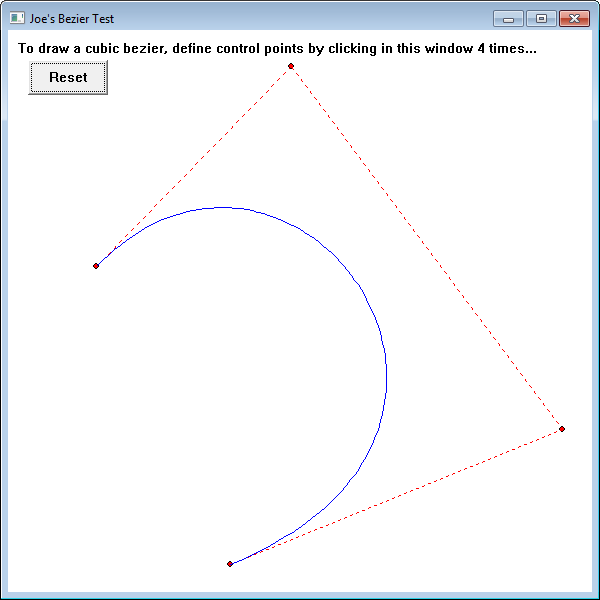
I just added full cubic bezier curve support to the vector tessellation creation tool I am developing (see here). I'll include some video at a later date (Update: here) showing this feature in action but first I want to document and make publicly available some of the code involved: namely, a bezie…
December 24, 2014

[font='Times New Roman']I've decided my "[/font]untitled Escher game[font='Times New Roman']
", i.e.[/font] Zoop[font='Times New Roman']
on a double logarithmic spiral, is going to be named "Draak", which is the Dutch word for dragon. The title bears no relation to the game beyond the fact that I …
November 16, 2014
Over the past several weeks I have been investigating desktop applications for creating novel Escher-like tilings of the plane. Basically I've determined that none of what is publicly available is useful to me. The game I have in development will involve an animated Escher-like tessellation of a do…
October 17, 2014
[color=rgb(51,51,51)][font=Georgia]I'm working on a puzzle game for iPads that takes the mechanics of a somewhat obscure game from the 1990s(*) and puts them on a double logarithmic spiral.[/font][/color]
[color=rgb(51,51,51)][font=Georgia] The final app will be styled similar to one of M. C. Escher…
[color=rgb(51,51,51)][font=Georgia] The final app will be styled similar to one of M. C. Escher…
October 02, 2014
Random numbers generated from a discrete distribution are commonly needed in game development.
By "discrete distibution" we just mean the roll you get from something like an unfair die, e.g. you want a random number from 0 to 5 but you want 4 and 5 to be twice as likely as 0, 1, 2, or 3. If we think…
By "discrete distibution" we just mean the roll you get from something like an unfair die, e.g. you want a random number from 0 to 5 but you want 4 and 5 to be twice as likely as 0, 1, 2, or 3. If we think…
August 16, 2014
Cocos2d-x releases since version 3 have broken compatibility with old tutorials. This can especially be a problem when you want to do something slightly non-standard from the point-of-view of Cocos2d-x.
If you want to use physics in a Cocos2d-x game the current standard way to do this is to use the …
If you want to use physics in a Cocos2d-x game the current standard way to do this is to use the …
July 26, 2014

My iPad game Zzazzy has made it through the review process and is now on the App Store: see here.
I will be updating the page I have for it here this week with more detailed instructions than what the app itself provides (There is a tutorial mode but it really just covers the basics), but basically …
I will be updating the page I have for it here this week with more detailed instructions than what the app itself provides (There is a tutorial mode but it really just covers the basics), but basically …
February 15, 2014
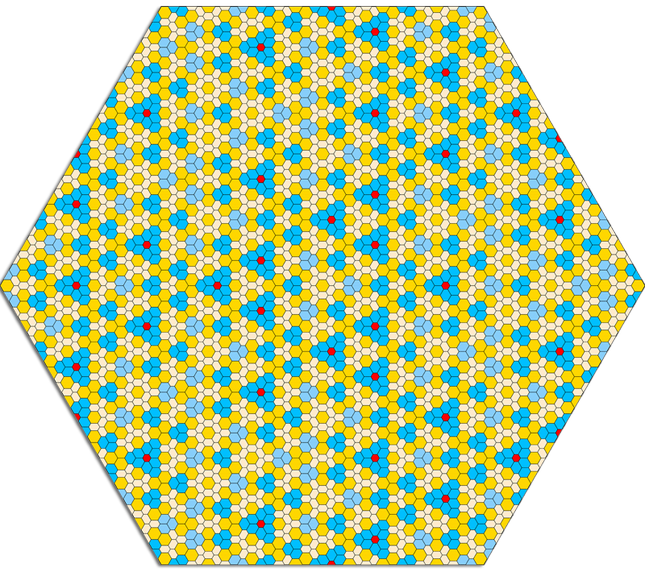
This summer coming up will be 20 years since the summer after I graduated from college. I'm currently in that golden period in between software jobs -- starting a new one in March -- and, given the free time, have just done something which I have been meaning to do since that summer.
I generated the…
I generated the…
August 20, 2013

February 12, 2013
For the game I'm working on I need to have sprites that travel along curving paths.
I'm talking about the sprites traveling along somewhat arbitrary curves, meaning curves that look good, not curves that result from gravity or other physical forces. If you need those kinds of curves, e.g. the parabo…
I'm talking about the sprites traveling along somewhat arbitrary curves, meaning curves that look good, not curves that result from gravity or other physical forces. If you need those kinds of curves, e.g. the parabo…
February 10, 2013

So, looking at the early entries of this blog, I must have started working on Syzygy around the beginning of the year 2012 because by March 2012 I had the Win32 prototype done. At that time, I didn't own a Macintosh, didn't own an iOS device, had never heard of cocos2d-x, and, professionally-wise, …
January 19, 2013

gamedev.net recently linked to this video about the making of Marble Madness, which got me thinking about the raster-to-vector via contour extraction code I wrote in Python last year and the fact that, it being the future and all, I can probably find all of the art from Marble Madness unrolled into…
January 06, 2013
I've been working on my puzzle game Syzygy again, after a long hiatus, and am now writing to iOS/cocos2d-x rather than just working on the prototype I had implemented to Win32.
The way that you get sprite data into cocos2d is by including as a resource a sprite sheet image and a .plist file which is…
The way that you get sprite data into cocos2d is by including as a resource a sprite sheet image and a .plist file which is…
December 30, 2012
This took me all morning to figure out. I'm posting here so there is clear information on this subject in at least one place on the internet.
The situation is this: when targeting iOS6 using Cocos2d-x v2.0.2, there is a bug in the auto-generated "Hello, World" code that shows up in a fresh project …
The situation is this: when targeting iOS6 using Cocos2d-x v2.0.2, there is a bug in the auto-generated "Hello, World" code that shows up in a fresh project …
March 16, 2012
I've started trying to figure out the way in which I'm going to port Syzygy to iOS. I don't actually own a Mac -- though I may get one this weekend -- so this is all theoretical at this point.
What I have right now is an implementation written in C++ to the Win32 API. Part of this implementation is …
What I have right now is an implementation written in C++ to the Win32 API. Part of this implementation is …
March 06, 2012

I'm releasing a prototype version of a puzzle game, Syzygy, that I intend eventually to port to iOS and possibly Android. The prototype is written to the Win32 API and should run on basically any Windows system without installing anything.
Syzygy can be downloaded here. Just unzip these three files …
Syzygy can be downloaded here. Just unzip these three files …
February 19, 2012
So this weekend I learned Python and implemented a basic raster to vector converter in it. It converts whatever file formats the Python PIL module supports to SVG.
Here's the little guys from Joust embedded as SVG (This probably doesn't work on Internet Explorer, but if you're using IE you have bigg…
Here's the little guys from Joust embedded as SVG (This probably doesn't work on Internet Explorer, but if you're using IE you have bigg…
February 12, 2012
There is a nice unscary Win32 API call for playing sounds that is unpretentiously called "PlaySound". It is extremely easy to use. Unfortunately, PlaySound(...) has one problem that makes it unsuitable for even casual game development: although it will play audio asynchronously, it will not play tw…
February 04, 2012
I don't know how long the Win32 API has included an AlphaBlend() function. I mean, it came in whenever Msimg32.lib did but I'm not sure when that was, probably Windows XP era, I guess.
It's always been a pain in the ass to use; easy to use global alpha but per-pixel is a chore. You see a lot of peop…
It's always been a pain in the ass to use; easy to use global alpha but per-pixel is a chore. You see a lot of peop…
Advertisement
Popular Blogs





{kind=link}
Advertisement