
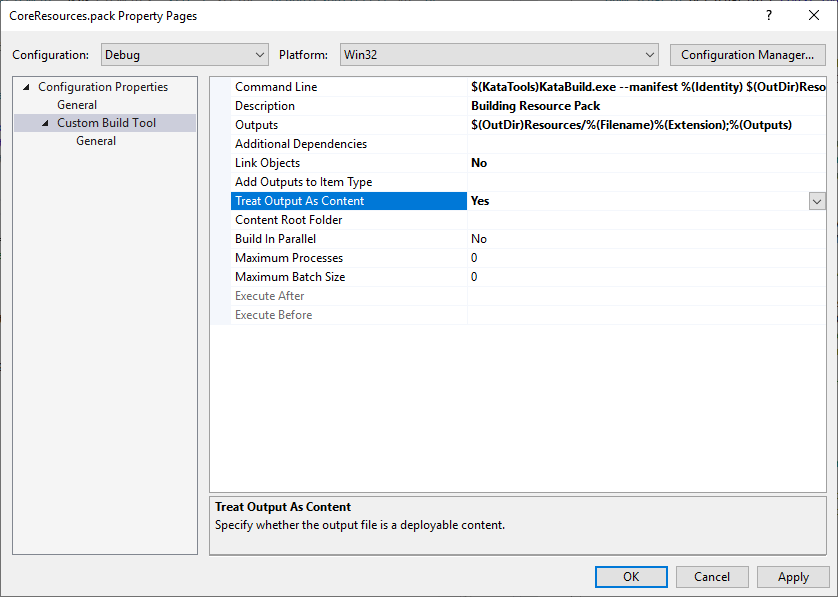
A few days ago I was setting up a new resource build pipeline for our games, and wanted to integrate the build directly in Visual Studio. The goal was to include a resource manifest file in the project, and have them be fed to my compiler as part of the normal VC project build. Often the starting …

If you’re unfamiliar with my DanceForce work or the previous versions, please read the introduction of my V3 build post for the rationale and advantages of this particular approach to a hard pad and what I’m going for. In short, th…

This is Part 1 of a series examining techniques used in game graphics and how those techniques fail to deliver a visually appealing end result. See Part 0 for a more thorough explanation of the idea behind it.
High dynamic range. First experienced by most consumers in late 2005, with Valve’s Half …

I’m about to start a series of blog posts called Games Look Bad. Before I start throwing stones from my glass house over here, I wanted to offer an explanation of what I’m doing and a defense of why I’m doing it.
There’s no doubt that we’ve seen a sustained and significant period of improvement in…

Today, we’re going to talk about how to configure a MIDI controller to act as a debugging aid for a game – or any software development project.
Why a MIDI controller? Photo credit: Wikimedia Commons / CC BY-SA 3.0Why would you want to do this? It’s very common to have a set of internal variables t…


I’m planning to review this camera properly at some point, but for the time being, I wanted to do a simple test of what the parameters of EVF lag and blackout are.
Let’s talk about lag first. What do we mean? The A77 II uses an electronic viewfinder, which means that the viewfinder is a tiny LCD p…

I was digging through my Ventspace post drafts, and I found this writeup that I apparently decided not to post. It was written in March of 2012, a full year and a half before the Xbox One arrived in the market. In retrospect, I’m apparently awesome. On the one hand, I wish I’d posted this up at th…

Some of you are probably working on Retina support and performance for your OpenGL based game for iOS devices. If you’re like us, you’re probably finding that a few of the devices (*cough* iPad 3) don’t quiiite have the GPU horsepower to drive your fancy graphics at retina resolutions. So now you’…

I’d hoped to write up a nice post for this, but unfortunately I haven’t had much time lately. Releasing a game, it turns out, is not at all relaxing. Work doesn’t end when you hit that submit button to Apple.
In the meantime, I happened to put together a video showing a prototype of the game, runn…
In the meantime, I happened to put together a video showing a prototype of the game, runnin…
After an incredibly long time of quiet development, our new game, I Am Dolphin, will be available this Thursday, October 9th, on the Apple/iOS App Store. This post will be discussing the background and the game itself; I’m planning to post more technical information about the game and development …

I’ve been in the process of building and testing a new machine using Intel’s new X99 platform. This platform, combined with the new Haswell-E series of CPUs, is the new high end of what Intel is offering in the consumer space. One of the pain points for developers is build time. For our part, we’r…

It’s good to review the fundamentals sometimes. Written in 1995 and often forgotten: A Pixel Is Not A Little Square.

I've been quiet for a very long time now, and this is why. We've just shipped our new game, Slug Bugs!
It uses our Ghost binaural audio which I've teased several times in the past, and is also wicked fun to play. Please …
Last time I talked about Mercurial, and was generally disappointed with it. I also evaluated Git, another major distributed version control system (DVCS).
Short Review: Quirky, but a promising winner.
Git, like Mercurial, was spawned as a result of the Linux-BitKeeper f…
I've been a long time Subversion user, and I'm very comfortable with its quirks and limitations. It's an example of a centralized version control system (CVCS), which is very easy to understand. However, there's been a lot of talk lately about distributed version control sy…
">YouTube link
Vimeo link (looks nicer)
Also can't help but notice that YouTube HD's encode quality is awful.
My last tech post was heavily negative, so today I'm going to try and be more positive. I've been working with a library called NHibernate, which is itself a port of a Java library called Hibernate. These are very mature, long-standing object relational mapping…
I find Windows Installer to be truly baffling. It's as close to the heart of Windows as any developer tool gets. It is technology which literally every single Windows user interacts with, frequently. I believe practically every single team at Microsoft works…
This is what we've been working on for the last several months at AR Labs.
Forget falls.
Forget tackles.
BioReplicant keeps walking.
info@actionreactionlabs.com for more information.
-----------------------
BioReplicants is a completely reactive procedural animation system f…
I'm working on some final touches for SlimTune's next version, and one of them involves persisting the launcher settings between application runs. Launching is handled by an interface ILauncher, which can be set to any number of things via a reflected list of inherited typ…
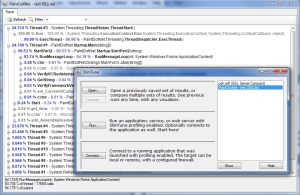
Here's a quick teaser of the new UI:
The window hosting the visualizer is missing all of its widgets, but will eventually have a variety of controls along the edges. The revised main SlimTune window is essentially complete. This window is always open…





{kind=link}