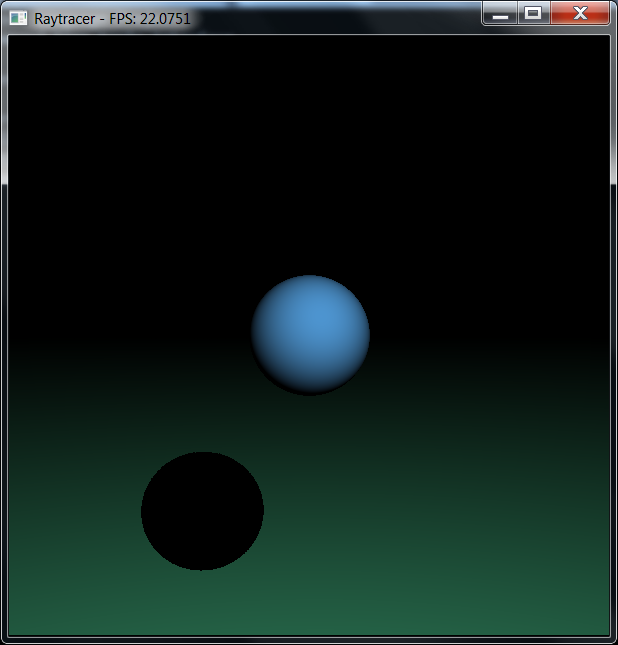
I've also experimented with the LLVM optimizers a bit and upgraded to version 3.2, which came with a couple of interesting speed boosts in the SIMD/vectorization department. Along the way, I decided to add some features to the realtime raytracer demo and threw in a ground plane and the ability for the sphere to cast shadows onto said plane.
The results should speak for themselves; keep in mind that the machine I'm running this on was pulling 17FPS with just the lit sphere a while ago. We're now up to 22+ FPS and that's with almost triple the number of rays being traced (intersection tests for the plane, plus shadow test rays).
Some of this has illuminated obvious weak spots in the language. Aside from a handful of bugs and dusty corner cases, there's one major issue that I really want to tackle next: object storage locations.
Epoch was envisioned as a handle-based language with a lot of garbage collection infrastructure and other niceties; creating an object of aggregate type (i.e a structure or "class" in the lingo of other languages) would always result in a free-store allocation, followed by perpetual costs for garbage collection checks until the object was finally no longer referenced and the memory could be reclaimed.
A major boost in speed for the language implementation involved moving away from handles to direct pointers; instead of a handle being used to look up the object's memory location and (optionally) its metadata, the handles themselves are just pointers to the object in memory. When looking up metadata, we use a reverse map to associate the pointer back to the metadata we need to see for the object, similar to vtables but with a little extra indirection overhead.
However, this is only a partial fix for the root problem, which is that storing aggregates is expensive. Any time you want a new one, you do a heap allocation and a couple of table fixups to store the metadata pointers. So creating an object in an inner loop, such as using a Point structure to compute a ray-object intersection test, can be extremely slow.
The solution, of course, is to eliminate indirections as much as possible. This comes in two flavors. First, structures need to be modified so that they are stored "flat" in memory whenever they can be; instead of nested objects being pointers to other bits of memory, the entire object should be crammed into a single buffer insofar as this is allowed by the shape of the class itself.
More importantly, though, we need a way to bypass the heap allocation entirely. In C++, this is done by allocating on the stack; in C#, it's done by allocating a struct instead of a class; in Java, it isn't possible at all without painful hacks. Most GC-enabled languages get around the heap allocation problem by offering really, really cheap allocations and then paying the cost on the tail-end during GC sweeps; this is not acceptable for me.
What I want to do is introduce storage specifiers into Epoch. They'll end up looking a bit like this:
// Create a stack objectinteger foo = 42// Bind a reference to some other object (note that like in C++ references cannot be reseated)integer ref bar = foo// Allocate a garbage-collected objectinteger new baz = 42// Allocate (then release) a manual-lifetime objectinteger manual quux = 42release(quux)Using the same knowledge that allows us to flatten structures in memory, we can also detect structures which have no references to external memory, enabling them to live in a faster garbage-collection "zone" that doesn't recursively check for live pointers. This further decreases the cost of garbage collection and makes it viable for the majority of operations. Combined with my planned thread-localized memory model and the inter-thread handoff model, it won't even be necessary to write a concurrent garbage collector to get excellent performance.
Moreover, since Epoch will rely on tasks (aka green threads) for most of its organizational structure, garbage collection becomes extremely cheap, since we don't have to walk the entire memory space of a program to collect for a single green thread. If you want memory to be shared, you hand it over to a different task, and as far as you're concerned it's now gone forever. Shared-nothing is a powerful model for concurrency and parallelism alike.
My roadmap for Release 14 is starting to look something like this:
- Create memory storage specifier support and implement it as widely as possible
- Update the raytracer demo to leverage this new model and prove that it works and is fast
- Rough in as much of the green-thread/task infrastructure as I have the patience for
- If this makes it a reasonable way towards completion, create a multithreaded raytracer for grins
I figure it this way. I can push 22 FPS on my machine with a single core. That leaves 7 other cores doing nothing. If I remove a little constant-time overhead for synchronizing and combining the render results at the end of each frame, I can still easily peak over 100FPS in a multithreaded renderer.
Assuming I don't run into any ridiculous headaches with that little scheme, R14 is going to be pretty damn amazing.

So cool, man - really!