Ostensibly, LLVM supports hooks for making garbage collection possible. It doesn't take much digging to find out that this is a complete lie, and LLVM is actually pretty terrible at interoperating with garbage collection schemes.
First of all, you can only mark stack allocations as holding GC roots. Registers must be spilled into stack values prior to running a GC pass or you can miss roots. More annoyingly, you can only declare GC root stack allocations in the prolog of a function - you can't mark them inside, say, the body of a loop. This means you either generate a lot of excess stack reads/writes, or you do something twisted to work around the problem.
I'm proud of Epoch's runtime performance right now, so I opted to go the twisted route.
The Epoch garbage collector will now only trigger on the exit from a function or after a certain number of iterations of a closed loop (to avoid excess memory consumption in tight loop code). This means that you will never trip a garbage collection in the middle of a complex expression, which in turn limits the number of stack hits I have to perform. So that much I can suffer through.
To do accurate garbage collection, we need three things:
- A map of all stack slots that can contain GC roots
- A way to get this map into the GC so it can use it
- A way to crawl the machine stack based on this map and begin mark/sweep tracing from the discovered roots
Except it doesn't.
What it does is create a stack map and then make it totally inaccessible to JIT frontends, which strikes me as more than a bit stupid. I quickly found the comment buried in the documentation suggesting that you can only access the stack map when outputting assembly language listings. WTF?! It was at this point that I started really feeling the truth that others have remarked about on the internet: LLVM just sucks for garbage collectors.
Me being stubborn and thick-headed, though, I decided to just plow forward and hope for the best.
I hacked around the unavailable stack map issue by implementing a custom GCStrategy class with CustomSafePoints set to true. When findCustomSafePoints() is called, I do the exact same logic as the LLVM default implementation of safe-point location, with two tweaks:
- All safe points are cached in a location accessible to the frontend (and, later, the GC as running against the JITted code)
- I actually implemented support for GC::Return safepoints so I can call garbage collection routines upon function exit. LLVM provides GC::Return and GC::Loop "kinds" of safepoints but then stupefyingly fails to implement support for either one.
Thankfully I've spent enough time doing reversing and assembly-level hacking that I'm comfortable with the idea of crawling the machine stack myself. It didn't take long to put together a function for this, although getting it to not clobber the machine state was a bit trickier.
There are two tricks to keep in mind when doing post-function-body garbage collection invocations:
- Back up an instruction before the RET before you CALL the garbage collector. This lets you inject the CALL prior to the POP EBP that destroys the function's stack frame and makes this whole exercise pointless.
- Don't forget that you were about to RET from a function; write some custom prolog/epilog code to ensure you don't clobber EAX during garbage collection. Or at least save it off someplace so you can restore it once you're done clobbering it.
So I wound up making a minor API tweak to the ExecutionEngine class in LLVM, adding in plumbing to get to the underlying JIT engine and ask for the address of the MCSymbol corresponding to the injected GC safe point. It took some minor arithmetic to adjust the reported address to line up with actual return addresses in each stack frame, but nothing too painful.
The results speak for themselves:
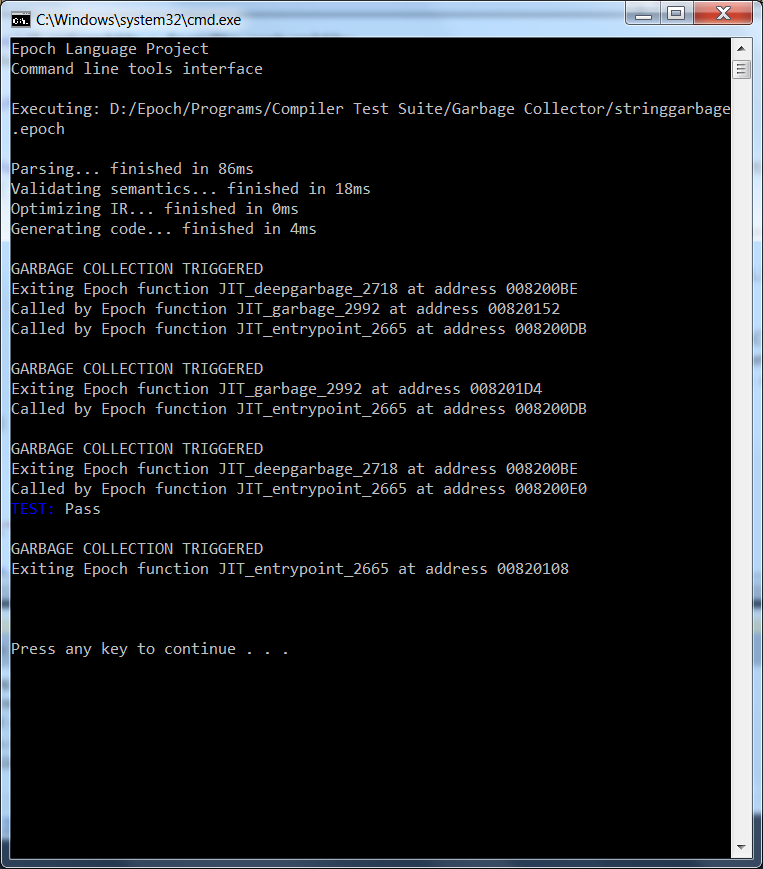
So as of now I have a working way to crawl the stack and look for GC roots. I'm starting out only supporting GC on strings since that's easier than dealing with all the other types in the language; but that'll come soon enough. I want to perfect the actual mark/sweep logic first and then mess with extending it to handle the whole type system.
Next step is to go through and actually do mark/sweep and emit a list of live strings versus garbage strings. Should be entertaining.
Overall, although I've been cursing at LLVM a lot today, it's not been too terrible. It certainly beats having to build my own machine code emission layer. Part of the reason I've stuck with it is because it does do a great job of just generating fast machine code, so I'm not totally convinced it's worth abandoning and using some other JIT engine, just for the sake of GC implementation.
If anything, I'd rather find ways to actually contribute some useful changes to LLVM that make the whole GC song and dance a little less unpleasant for the next guy.



