
Hi everyone,
I am attempting to render 1,000,000 sprites on my screen at 60 FPS. I am using OpenGL persistent mapping.
At first, I was using glMapBuffer to do this and I was getting around 32 frames. After using glMapBufferRange / persistent mapping I started getting 34 frames. I have been trying to profile my code and figure out what is going on, and for the life of me, I can't. I know my GPU is just sitting mostly idle. So it is a CPU bottleneck. I fired up VS 2019 CPU profiler and tried to see why my CPU bottlenecked and I can't figure it out. All I know is that my CPU is spending around 70% of its time in the function that maps the sprite
I am building this in release x64 bit mode
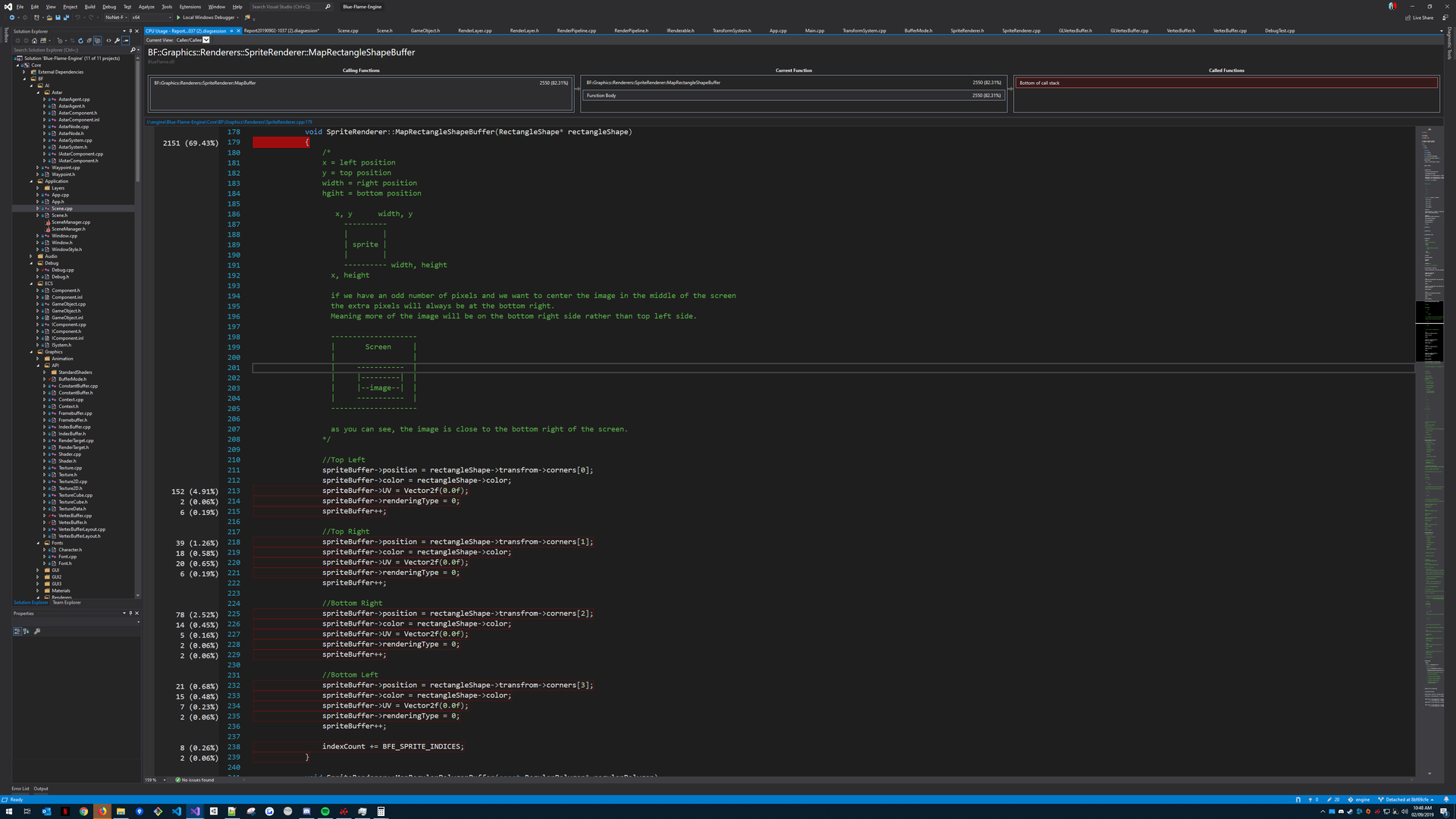
What am I supposed to do with the information that my CPU is spending 69% of its time on the opening curly brace??
My render loop is simple enough and it looks like this
#define BFE_MAX_SPRITES 1000000
#define BFE_SPRITE_VERTICES 4
#define BFE_SPRITE_INDICES 6
#define BFE_VERTICES_SIZE BFE_MAX_SPRITES * BFE_SPRITE_VERTICES
#define BFE_INDICES_SIZE BFE_MAX_SPRITES * BFE_SPRITE_INDICES
void SpriteRenderer::Initialize()
{
BF::Engine::GetContext().SetPrimitiveType(PrimitiveType::Triangles);
shader.LoadStandardShader(ShaderType::SpriteRenderer);
vertexBufferLayout.Push(0, "POSITION", VertexBufferLayout::DataType::Float2, sizeof(SpriteBuffer), 0);
vertexBufferLayout.Push(1, "COLOR", VertexBufferLayout::DataType::Float4, sizeof(SpriteBuffer), sizeof(Vector2f));
vertexBufferLayout.Push(2, "TEXCOORD", VertexBufferLayout::DataType::Float2, sizeof(SpriteBuffer), sizeof(Vector2f) + sizeof(Color));
vertexBufferLayout.Push(3, "RENDERINGTYPE", VertexBufferLayout::DataType::Float, sizeof(SpriteBuffer), sizeof(Vector2f) + sizeof(Color) + sizeof(Vector2f));
unsigned int* indices = new unsigned int[BFE_INDICES_SIZE];
int index = 0;
/*
Winding order is clock-wise.
0 -> 1 -> 2 ---> 2 -> 3 -> 0
0 1
______
|\ |
| \ |
| \ |
| \ |
| \ |
|_____\|
3 2
*/
for (unsigned int i = 0; i < BFE_INDICES_SIZE; i += BFE_SPRITE_INDICES)
{
indices[i + 0] = index + 0;
indices[i + 1] = index + 1;
indices[i + 2] = index + 2;
indices[i + 3] = index + 2;
indices[i + 4] = index + 3;
indices[i + 5] = index + 0;
index += BFE_SPRITE_VERTICES;
}
vertexBuffer.Create();
vertexBuffer.Allocate(BFE_VERTICES_SIZE * sizeof(SpriteBuffer), nullptr, BufferMode::PersistentMapping);
ogSpriteBuffer = (SpriteBuffer*)vertexBuffer.MapPersistentStream();
spriteBuffer = ogSpriteBuffer;
indexBuffer.Create();
indexBuffer.SetBuffer(indices, BFE_INDICES_SIZE, BufferMode::StaticDraw);
vertexBuffer.SetLayout(shader, &vertexBufferLayout);
Engine::GetContext().EnableDepthBuffer(false);
Engine::GetContext().EnableBlending(true);
Engine::GetContext().EnableScissor(true);
delete[] indices;
}
void SpriteRenderer::Render()
{
totalDrawCalls = 0;
shader.Bind();
MapBuffer();
vertexBuffer.Bind();
indexBuffer.Bind();
Engine::GetContext().Draw(indexCount);
indexBuffer.Unbind();
vertexBuffer.Unbind();
totalDrawCalls++;
indexCount = 0;
currentBoundTexture = nullptr;
spriteBuffer = ogSpriteBuffer;
}
void SpriteRenderer::MapBuffer()
{
if (submitSprite)
{
for (size_t i = 0; i < renderLayerManager.renderLayers.size(); i++)
{
for (size_t j = 0; j < renderLayerManager.renderLayers[i]->renderables.size(); j++)
{
MapRectangleShapeBuffer((RectangleShape*)renderLayerManager.renderLayers[i]->renderables[j]);
}
}
}
}
void SpriteRenderer::MapRectangleShapeBuffer(RectangleShape* rectangleShape)
{
//Top Left
spriteBuffer->position = rectangleShape->transfrom->corners[0];
spriteBuffer->color = rectangleShape->color;
spriteBuffer->UV = Vector2f(0.0f);
spriteBuffer->renderingType = 0;
spriteBuffer++;
//Top Right
spriteBuffer->position = rectangleShape->transfrom->corners[1];
spriteBuffer->color = rectangleShape->color;
spriteBuffer->UV = Vector2f(0.0f);
spriteBuffer->renderingType = 0;
spriteBuffer++;
//Bottom Right
spriteBuffer->position = rectangleShape->transfrom->corners[2];
spriteBuffer->color = rectangleShape->color;
spriteBuffer->UV = Vector2f(0.0f);
spriteBuffer->renderingType = 0;
spriteBuffer++;
//Bottom Left
spriteBuffer->position = rectangleShape->transfrom->corners[3];
spriteBuffer->color = rectangleShape->color;
spriteBuffer->UV = Vector2f(0.0f);
spriteBuffer->renderingType = 0;
spriteBuffer++;
indexCount += BFE_SPRITE_INDICES;
}
I don't know where to go from here





