In my original method the resulting sphere had a slight crease along the equator where the quantization error was worst. In the new method there is less error overall, and more importantly the quantization error is spread more evenly, eliminating the equatorial crease.



In the first image is a sphere lit using full 12 byte normals. The second image is the same sphere lit using the improved quantization method. You can see that both of them look perfectly spherical. There is no visible loss of accuracy from the new quantization method. By comparison the old quantization method shows a crease along the equator. I have included code for the new quantization method at the bottom of this article. Here is a quick explanation of how this improved quantization method works, borrowing extensively from Oleg's own explanation of the algorithm.
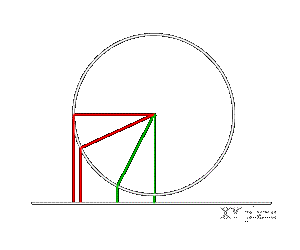
In my old quantization method I was basically projecting a sphere onto the XY plane. Therefore the quantization method was pretty good in places where the sphere surface is not perpendicular to the plane, but gets progressively worse as the surface becomes perpendicular to the projection plane. You can see in the diagram that normals in the red area map to a much smaller part of the plane than normals in the green area. More specificaly adding 2 bits to the sample size generally increases the accuracy by a factor 4 but near the edges the accuracy increases only twice.
One way to avoid this effect is to use another type of projection. By selecting a radial projection on the plane that goes through points X0=(1,0,0),Y0={0,1,0) and Z0=(0,0,1). That is, one casts a ray from the origin to the given point on the sphere and finds the intersection between the ray and the plane. To simplify things even further the new method uses a non-orthogonal coordinate system on the plane such that X0->(0,0), Y0->(1,0), Z0->(0,1)
Since we only consider the octant where x,y,z > 0, the sphere is nowhere perpendicular to the plane. In fact the maximum angle between the sphere and the plane is around 30 degrees. In this case the projection is everywhere nice and regular and each bit of the sample always corresponds to a 2-fold increase in accuracy. Calculations show that the spread between the maximum accuracy and the minimal accuracy is only about 5 times.
The formula for the projective transform is:
[font="Courier New"][color="#000080"][bquote]zbits = 1/3 * (1 - (x+y-2*z)/(x+y+z))
ybits = 1/3 * (1 - (x-2*y+z)/(x+y+z))[/bquote][/color][/font]
Which we can reduce to: ybits = 1/3 * (1 - (x-2*y+z)/(x+y+z))[/bquote][/color][/font]
[font="Courier New"][color="#000080"][bquote]zbits = z / ( x + y + z )
ybits = y / ( x + y + z )[/bquote][/color][/font]
The ybits and zbits are now between 0 and 1, and so is ( ybits + zbits ). Thus we can apply a similar bit-packing method as in the original algorithm. In the original method since the diagonal of the table was all zero, we could quantize two values, x and y, from 0-127, since the diagonal could be shared in the two encodings. Since in this mapping the diagonal varies, we have to quantize two values ybits and zbits from 0-126 so that we code nothing on the diagonal. ybits = y / ( x + y + z )[/bquote][/color][/font]
To unpack we use the reverse transform and then normalize the vector so it again lies on the sphere. Since normalization is just a scaling by some number, we can pre-tabulate the amount of required scaling for each u and v and thus avoid costly divisions and square roots. Logically what we do is:
[font="Courier New"][color="#000080"][bquote]scaling = scalingTable[zbits][ybits]
v.z = zbits * scaling
v.y = ybits * scaling
v.x = (1 - zbits - ybits ) * scaling[/bquote]
[/color][/font]
There is another way to understand this new projection. We know the length of unit vectors is always 1, so we don't have to store that information. We can store any vector that is colinear with the normal as the quantized vector and then just normalize the vector once we unpack it ( by multiplying it with a stored normalization constant ). So all we need to do is store the ratio of say x/(x+y+z) and y/(x+y+z) as our two quantized values. Any ratios that allow us to resconstruct the proportions of x,y,z will do. Since we are quantizing the values in the range 0-126 just do the following: v.z = zbits * scaling
v.y = ybits * scaling
v.x = (1 - zbits - ybits ) * scaling[/bquote]
[/color][/font]
[font="Courier New"][color="#000080"][bquote]w = 126 / ( x + y + z )
xbits = x * w;
ybits = y * w;[/bquote][/color][/font]
Now xbits is the ratio of x/(x+y+z) quantized in the range of 0-126, and ybits is the ratio y/(x+y+z). Given these two ratios we can unpack a vector colinear with the original vector like so: xbits = x * w;
ybits = y * w;[/bquote][/color][/font]
[font="Courier New"][color="#000080"][bquote]x = xbits
y = ybits
z = 126 - x - y[/bquote][/color][/font]
Finally to get the original normal back, we just multiply the unpacked vector by the appropriate scaling constant: y = ybits
z = 126 - x - y[/bquote][/color][/font]
[font="Courier New"][color="#000080"][bquote]x *= scaling;
y *= scaling;
z *= scaling;[/bquote][/color][/font]
A quick review should convince you that both methods are in fact identical. y *= scaling;
z *= scaling;[/bquote][/color][/font]
This new method has a slightly higher cost. To pack a vector from 12 bytes to 2 bytes the old method used 4 multiplies and 2 adds, this new method requires 2 multiplies, 2 adds and a divide, which on modern processors may be almost the same speed. The unpacking method costs 3 extra multiplies and two adds. Also no big deal. And look at that near perfect accuracy, at least for lighting.
Below is a reimplementation of the original quantized vector class with the improved quantization method.
#ifndef _3D_UNITVEC_H
#define _3D_UNITVEC_H
#include
#include
#include "3dmath/vector.h"
#define UNITVEC_DECLARE_STATICS \
float cUnitVector::mUVAdjustment[0x2000]; \
c3dVector cUnitVector::mTmpVec;
// upper 3 bits
#define SIGN_MASK 0xe000
#define XSIGN_MASK 0x8000
#define YSIGN_MASK 0x4000
#define ZSIGN_MASK 0x2000
// middle 6 bits - xbits
#define TOP_MASK 0x1f80
// lower 7 bits - ybits
#define BOTTOM_MASK 0x007f
// unitcomp.cpp : A Unit Vector to 16-bit word conversion algorithm
// based on work of Rafael Baptista (rafael@oroboro.com)
// Accuracy improved by O.D. (punkfloyd@rocketmail.com)
//
// a compressed unit vector. reasonable fidelty for unit vectors in a 16 bit
// package. Good enough for surface normals we hope.
class cUnitVector : public c3dMathObject
{
public:
cUnitVector() { mVec = 0; }
cUnitVector( const c3dVector& vec )
{
packVector( vec );
}
cUnitVector( unsigned short val ) { mVec = val; }
cUnitVector& operator=( const c3dVector& vec )
{ packVector( vec ); return *this; }
operator c3dVector()
{
unpackVector( mTmpVec );
return mTmpVec;
}
void packVector( const c3dVector& vec )
{
// convert from c3dVector to cUnitVector
assert( vec.isValid());
c3dVector tmp = vec;
// input vector does not have to be unit length
// assert( tmp.length() <= 1.001f );
mVec = 0;
if ( tmp.x < 0 ) { mVec |= XSIGN_MASK; tmp.x = -tmp.x; }
if ( tmp.y < 0 ) { mVec |= YSIGN_MASK; tmp.y = -tmp.y; }
if ( tmp.z < 0 ) { mVec |= ZSIGN_MASK; tmp.z = -tmp.z; }
// project the normal onto the plane that goes through
// X0=(1,0,0),Y0=(0,1,0),Z0=(0,0,1).
// on that plane we choose an (projective!) coordinate system
// such that X0->(0,0), Y0->(126,0), Z0->(0,126),(0,0,0)->Infinity
// a little slower... old pack was 4 multiplies and 2 adds.
// This is 2 multiplies, 2 adds, and a divide....
float w = 126.0f / ( tmp.x + tmp.y + tmp.z );
long xbits = (long)( tmp.x * w );
long ybits = (long)( tmp.y * w );
assert( xbits < 127 );
assert( xbits >= 0 );
assert( ybits < 127 );
assert( ybits >= 0 );
// Now we can be sure that 0<=xp<=126, 0<=yp<=126, 0<=xp+yp<=126
// however for the sampling we want to transform this triangle
// into a rectangle.
if ( xbits >= 64 )
{
xbits = 127 - xbits;
ybits = 127 - ybits;
}
// now we that have xp in the range (0,127) and yp in the range (0,63),
// we can pack all the bits together
mVec |= ( xbits << 7 );
mVec |= ybits;
}
void unpackVector( c3dVector& vec )
{
// if we do a straightforward backward transform
// we will get points on the plane X0,Y0,Z0
// however we need points on a sphere that goes through these points.
// therefore we need to adjust x,y,z so that x^2+y^2+z^2=1
// by normalizing the vector. We have already precalculated the amount
// by which we need to scale, so all we do is a table lookup and a
// multiplication
// get the x and y bits
long xbits = (( mVec & TOP_MASK ) >> 7 );
long ybits = ( mVec & BOTTOM_MASK );
// map the numbers back to the triangle (0,0)-(0,126)-(126,0)
if (( xbits + ybits ) >= 127 )
{
xbits = 127 - xbits;
ybits = 127 - ybits;
}
// do the inverse transform and normalization
// costs 3 extra multiplies and 2 subtracts. No big deal.
float uvadj = mUVAdjustment[mVec & ~SIGN_MASK];
vec.x = uvadj * (float) xbits;
vec.y = uvadj * (float) ybits;
vec.z = uvadj * (float)( 126 - xbits - ybits );
// set all the sign bits
if ( mVec & XSIGN_MASK ) vec.x = -vec.x;
if ( mVec & YSIGN_MASK ) vec.y = -vec.y;
if ( mVec & ZSIGN_MASK ) vec.z = -vec.z;
assert( vec.isValid());
}
static void initializeStatics()
{
for ( int idx = 0; idx < 0x2000; idx++ )
{
long xbits = idx >> 7;
long ybits = idx & BOTTOM_MASK;
// map the numbers back to the triangle (0,0)-(0,127)-(127,0)
if (( xbits + ybits ) >= 127 )
{
xbits = 127 - xbits;
ybits = 127 - ybits;
}
// convert to 3D vectors
float x = (float)xbits;
float y = (float)ybits;
float z = (float)( 126 - xbits - ybits );
// calculate the amount of normalization required
mUVAdjustment[idx] = 1.0f / sqrtf( y*y + z*z + x*x );
assert( _finite( mUVAdjustment[idx]));
//cerr << mUVAdjustment[idx] << "\t";
//if ( xbits == 0 ) cerr << "\n";
}
}
void test()
{
#define TEST_RANGE 4
#define TEST_RANDOM 100
#define TEST_ANGERROR 1.0
float maxError = 0;
float avgError = 0;
int numVecs = 0;
{for ( int x = -TEST_RANGE; x < TEST_RANGE; x++ )
{
for ( int y = -TEST_RANGE; y < TEST_RANGE; y++ )
{
for ( int z = -TEST_RANGE; z < TEST_RANGE; z++ )
{
if (( x + y + z ) == 0 ) continue;
c3dVector vec( (float)x, (float)y, (float)z );
c3dVector vec2;
vec.normalize();
packVector( vec );
unpackVector( vec2 );
float ang = vec.dot( vec2 );
ang = (( fabs( ang ) > 0.99999f ) ? 0 : (float)acos(ang));
if (( ang > TEST_ANGERROR ) | ( !_finite( ang )))
{
cerr << "error: " << ang << endl;
cerr << "orig vec: " << vec.x << ",\t" << vec.y << ",\t"
<< vec.z << "\tmVec: " << mVec << endl;
cerr << "quantized vec2: " << vec2.x << ",\t" << vec2.y << ",\t"
<< vec2.z << endl << endl;
}
avgError += ang;
numVecs++;
if ( maxError < ang ) maxError = ang;
}
}
}}
for ( int w = 0; w < TEST_RANDOM; w++ )
{
c3dVector vec( genRandom(), genRandom(), genRandom());
c3dVector vec2;
vec.normalize();
packVector( vec );
unpackVector( vec2 );
float ang =vec.dot( vec2 );
ang = (( ang > 0.999f ) ? 0 : (float)acos(ang));
if (( ang > TEST_ANGERROR ) | ( !_finite( ang )))
{
cerr << "error: " << ang << endl;
cerr << "orig vec: " << vec.x << ",\t" << vec.y << ",\t"
<< vec.z << "\tmVec: " << mVec << endl;
cerr << "quantized vec2: " << vec2.x << ",\t" << vec2.y << ",\t"
<< vec2.z << endl << endl;
}
avgError += ang;
numVecs++;
if ( maxError < ang ) maxError = ang;
}
{ for ( int x = 0; x < 50; x++ )
{
c3dVector vec( (float)x, 25.0f, 0.0f );
c3dVector vec2;
vec.normalize();
packVector( vec );
unpackVector( vec2 );
float ang = vec.dot( vec2 );
ang = (( fabs( ang ) > 0.999f ) ? 0 : (float)acos(ang));
if (( ang > TEST_ANGERROR ) | ( !_finite( ang )))
{
cerr << "error: " << ang << endl;
cerr << "orig vec: " << vec.x << ",\t" << vec.y << ",\t"
<< vec.z << "\tmVec: " << mVec << endl;
cerr << " quantized vec2: " << vec2.x << ",\t" << vec2.y << ",\t"
<< vec2.z << endl << endl;
}
avgError += ang;
numVecs++;
if ( maxError < ang ) maxError = ang;
}}
cerr << "max angle error: " << maxError
<< ", average error: " << avgError / numVecs
<< ", num tested vecs: " << numVecs << endl;
}
friend ostream& operator<< ( ostream& os, const cUnitVector& vec )
{ os << vec.mVec; return os; }
protected:
unsigned short mVec;
static float mUVAdjustment[0x2000];
static c3dVector mTmpVec;
};
#endif // _3D_VECTOR_H


Search for your code on google you will find that Valve took your code and copyrighted it their own. Your name is still in the comments though. I hope you don't mind ! heh.. :)
btw, I'm also taking it. I hope it will serve my needs.
Do you think you could describe that method as being a projection on a cube or a tetrahedron of sorts, rather than 2 planes ?