The motivation
My current project includes a small maze game with a simple perspective (see screenshot). Each frame the entire screen is redrawn; first the ground tiles, then all sprites with height (trees, pick-up's, characters). Drawing the ground tiles is pretty straightforward. The sprites, however, have to be drawn in the correct order; sorted by their y-position. Since the sprites move around in the maze, their y-position will change and with it, their position in the drawing order.

Screenshot of the game by Three Little Witches
So for this game I needed a data structure with following properties:
- It can be traversed quickly (the drawing loop)
- It is sorted (need the drawing order)
- Elements in the sorted dataset can change value (y position of sprites can change)
(Changing the sort value of an element in a sorted dataset can be accomplished by deleting the old value and inserting the new one) - It can have duplicates (sprites can be at the same y position)
Choices
Google came up with a red-black tree, a balanced binary search tree that has quite fast insert and delete operations and is always sorted. Unfortunately, it doesn't allow duplicates and traversing the data in sorted order (done every frame) is fast but involves some calculations.
Combining the doubly linked list with the red-black tree results in a data structure that can have duplicates and has a fast and ordered traversal.
Doubly linked list

The doubly linked list is a basic data structure and plenty of information about it is available on the web. Because universities usually put their lecture slides online in PowerPoint format, a Google search for "site:edu filetype:ppt doubly linked list" results in excellent links to presentations about this data structure.
The individual nodes that make up the list have the following definition
struct DLLNode { int Key; DLLNode * Next; DLLNode * First; };
Binary search tree
Binary search trees have been around for some time and you can find some great presentations for it with a Google.

The problem with a 'normal' binary search tree is imbalance. If we insert the numbers 9, 8, 7, 6, 5, 4, 3, 1 in that order the tree wouldn't look much like a tree. In fact, it looks and acts just as a doubly linked list does and its search and insert operation would be just as slow.
Red-black tree
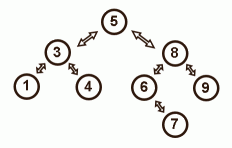
To prevent this situation, the tree needs to stays balanced (look like a proper upside-down tree). Adelson-Velskii and Landis invented the first self-balancing tree in 1962 (AVL tree) and a red-black tree is much alike. Because the tree stays balanced, search and insert operations are guaranteed to be fast, no matter what order the data is inserted or deleted.
To make this self-balancing work, a red-black tree needs to do some housekeeping each time you insert or delete something from the tree. If the newly inserted or just deleted node upsets the balance, the tree needs to fix it.
Essentially, the red-black tree uses rotations to keep itself balanced. I found it quite confusing and I drew hundreds of little connected circles before it made some sense. It is all very neat though, so do a Google for "site:edu filetype:ppt red black tree".
The individual nodes that make up the tree have the following definition:
struct RBTreeNode { int Key; RBTreeNode * Left; RBTreeNode * Right; RBTreeNode * Parent; int Color; };
Red-black tree with a doubly linked list
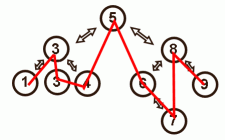
(red lines show the doubly linked list connections)
When the doubly linked list is combined with the red-black tree the new node definition looks like this:
struct CombinedNode { int Key; CombinedNode * Left; CombinedNode * Right; CombinedNode * Parent; int Color; CombinedNode * Next; CombinedNode * Prev; }; Every node is linked in both the tree (Left, Right, Parent) and in the list (Next, Prev). This results in two traversal methods through the data; using the tree links (slower) or the list links (faster). The tree traversal can be used to traverse only the unique values and comes in use when inserting a new node in the doubly linked list. The list traversal can be used to run through all the data in a sorted order, including duplicates.
The usual insert and delete operation of a red-black tree need to be changed:
Insert operation
First a regular insert in the tree is done. There are three possible outcomes:
- Insert failed because a duplicate is present in the tree
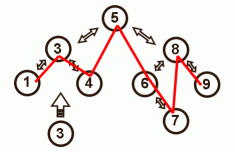
If a duplicate is found in the tree (3) the new node isn't inserted in the tree but it still needs to get linked in the list. Get the next node of the existing duplicate using the tree traversal (4). Insert the new node before it. - The new element is a left leaf in the tree
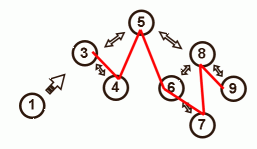
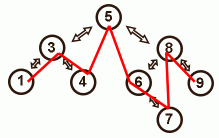
Link the new element (1) in the list before the parent (3). - The new element is a right leaf in the tree
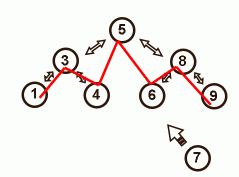
Since the new node (7) is already inserted in the tree, we can use the tree traversal to get the next (8). Insert the new node in the list before it.
Delete operation
Before we delete a node from the tree check for three situations:
- The node has duplicates and is not in the tree
Simply delete the node from the list. The tree hasn't changed. - The node has duplicates and is linked in the tree (first of the duplicates)
Delete the node from the list. The tree structure isn't changed as the next duplicate takes the place of the deleted node in the tree. - The node has no duplicates
Delete the node from the list and delete it from the tree.
Definition
For my maze game I needed to store sprites by their y position. With the tree/list combination in mind I came up with the following class definition:
class TStorage { public: TStorage(); ~TStorage(); TStorageNode * Insert(int key, TSprite * data); void Delete(TStorageNode * node); void ReplaceKey(TStorageNode * node, int newkey); void Clear(); TStorageNode * GetFirst(); TStorageNode * GetLast(); private: TStorageNode * First; TStorageNode * Last; TStorageNode * Root; ... }; Notice that the Insert(...) method returns a TStorageNode *. We need that node to refer to it later if we want to change the key or delete it. Insert(int key, Tsprite * sprite) also takes a TSprite * as a parameter that is stored with the key.
Since the data contained in TStorageNode should only be changed by TStorage, I protected them and declare TStorage a friend. Here's the definition:
class TStorageNode { public: TStorageNode * GetNext() { return Next; } TStorageNode * GetPrev() { return Prev; } int GetKey() { return Key; } TSprite * GetSprite() { return Sprite; } void SetSprite(TSprite * newspr) { Sprite = newspr; } private: friend class TStorage; TStorageNode * Next; TStorageNode * Prev; TStorageNode * Left; TStorageNode * Right; TStorageNode * Parent; TStorageColor Color; int Key; TSprite * Sprite; };
Using it
At the start of the game all sprites are added to the storage object:
void SpriteAdd(TStorage * storage, TSprite * sprite) { TStorageNode * node; node = storage->Insert(sprite->ypos, sprite); sprite->Node = node; } Because the y position of the sprite (the key in the storage) can change during the game, the created node is stored in the sprite so we can refer to it later. This happens in the game's update loop where the sprite positions get updated:
void SpriteChanged(TStorage * storage, TSprite * sprite) { if (sprite->Node->GetKey() != sprite->ypos) storage->ReplaceKey(sprite->node, sprite->ypos); } If sprites get deleted we have to take then out of the storage before they are freed:
void SpriteRemove(TStorage * storage, TSprite * sprite) { storage->Delete(sprite->Node); } Finally, in the drawing loop, we need to traverse through all the sprites and draw them:
void SpriteDrawSorted(TStorage * storage) { TStorageNode * node; for ( node = storage->GetFirst(); node != NULL; node = node->GetNext()) { node->GetSprite()->Draw(); } } The code snippets above solved the drawing order problem in the maze.
The template bit
The current definition of TStorage uses an int as key type and a Tsprite * as userdata. This makes the data structure only useful for the drawing problem. To make it more flexible a template can be used.
I've mixed feelings about templates. They seem very useful and can solve many type related issues especially with container classes such as TStorage. However, in my experience, many programmers get confused by them and the compiler errors and warnings look very daunting. The STL (Standard Template Library) in C++ isn't used as much as would be expected from a library full of so many useful structures. It's like the washing machine issue; the manufacturers, after years of research, claim the new interface is the most user friendly possible. Men still generally don't use them, claiming they can't operate them. Who's wrong?
Rewriting TStorage for templates
See the full source code for the complete implementation but to show the changes:
template <class K, class D> class TStorage { public: TStorage(); ~TStorage(); TStorageNode * Insert(const T &key, const D &data); void Delete(TstorageNode * node); ... } Looks ugly, doesn't it? And TStorageNode now looks like this:
template <class K, class D> class TStorageNode { public: TStorageNode * GetNext() { return Next; } TStorageNode * GetPrev() { return Prev; } K GetKey() { return Key; } D GetData() { return Data; } void SetData(const D &userdata) { Data = userdata; } private: friend class TStorage; TStorageNode * Next; TStorageNode * Prev; TStorageNode * Left; TStorageNode * Right; TStorageNode * Parent; TStorageColor Color; K Key; D Data; }; To get the original class that stores TSprite * with the integer key:
typedef TStorage<int, TSprite *> TSpriteStorage; typedef TStorageNode<int, TSprite *> TspriteStorageNode; Note that the TStorage uses the operators < and > to compare the keys. So the type you define as key must have those operators implemented. If not, you will get a compiler error in the template code.
About the speed
There is an overhead for keeping the tree balanced, sorted and maintaining the list. As the amount of nodes increase, the overhead increases. However, the extra overhead is only slightly dependent on the number of nodes. Slightly meaning Olog[sub]2[/sub]N, where O is a constant and N is the number of nodes.
Number of nodes (N) ~log[sub]2[/sub]N 10 3 100 7 1,000 10 10,000 13 100,000 17 1,000,000 20 If there is overhead Q at 1000 nodes, and you then use 100 times as many nodes, there won't be a overhead of 100*Q but only 1.7*Q.
So whether a TStorage object holds large or small amounts of data, its Insert(...), Delete(...) and ReplaceKey(...)GetPrev() and GetNext() always execute in constant time (=independent of the number of nodes).
The source code
I borrowed freely from Emin Martinian (http://www.csua.berkeley.edu/~emin/index.html) for the implementation of the red-black tree.
The final implementation includes some extra methods (such as Find) that I didn't discuss in this article. You can download the source code here and you may use it as you wish but at your own risk.
Arjan van den Boogaard
[email="arjan@threelittlewitches.nl"]arjan@threelittlewitches.nl[/email]
www.threelittlewitches.nl

